前言
在了解TinyKV中提到的badger过程中学习到LSM-Tree,故此记录
什么是LSM-Tree
LSM-Tree全称为Log-Structured Merge-Tree,日志结构合并树,下文简称LSM-Tree。LSM-Tree的架构分为内存部分和有序的磁盘部分,内存部分实现高速写,有序的硬盘实现高效查,整体架构如下图中LevelDB所示。
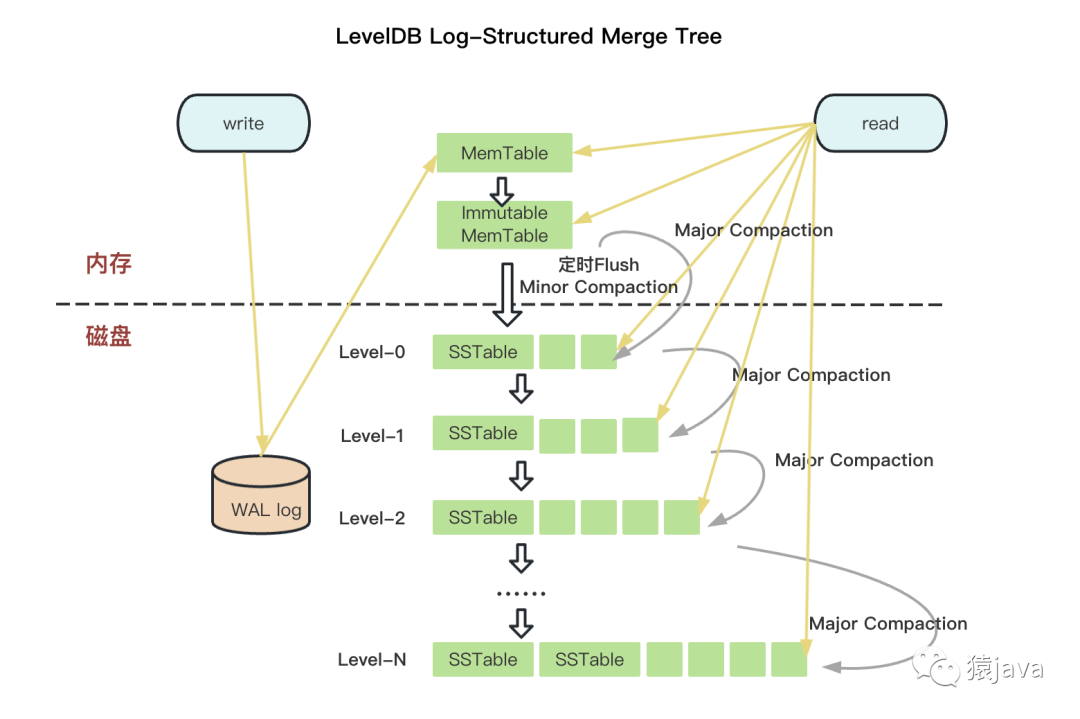
LSM-Tree的思想是:借助于内存和日志文件将写入过程分为时间上不前后相连的两步,写入是只顺序写入磁盘的日志文件和内存,等系统空闲时再将内存中数据写入到磁盘。这样在处理写入请求时就省去了磁盘寻道、转动磁头的时间。
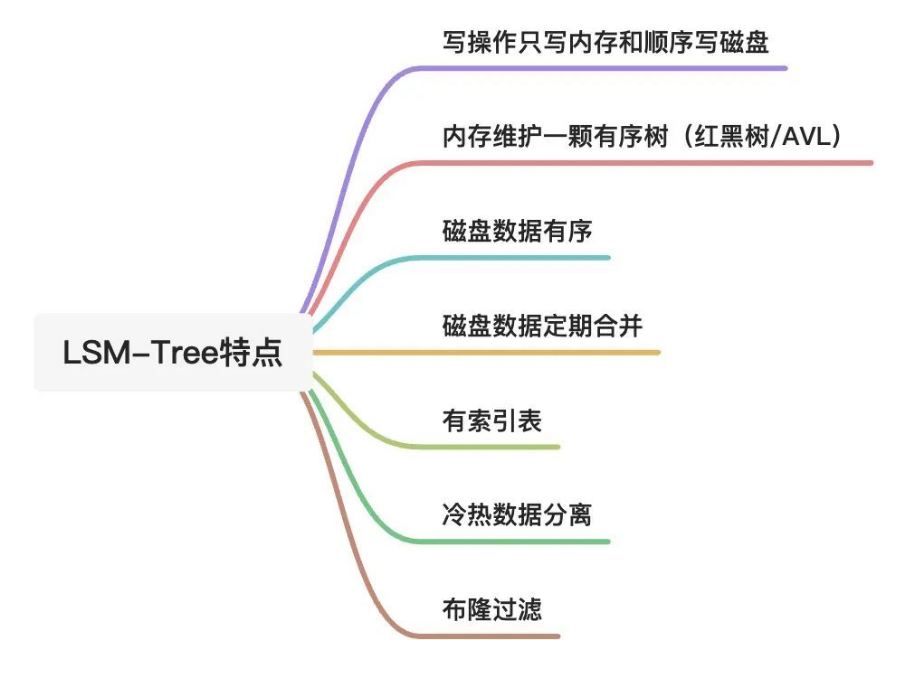
LSM-Tree有以下几个特点:
LSM-Tree工作原理
LSM-tree 核心是将写入操作与合并操作分离,通过将数据写入日志文件和内存缓存,然后定期进行合并操作来提高写入和查询的性能。
LSM-Tree写入
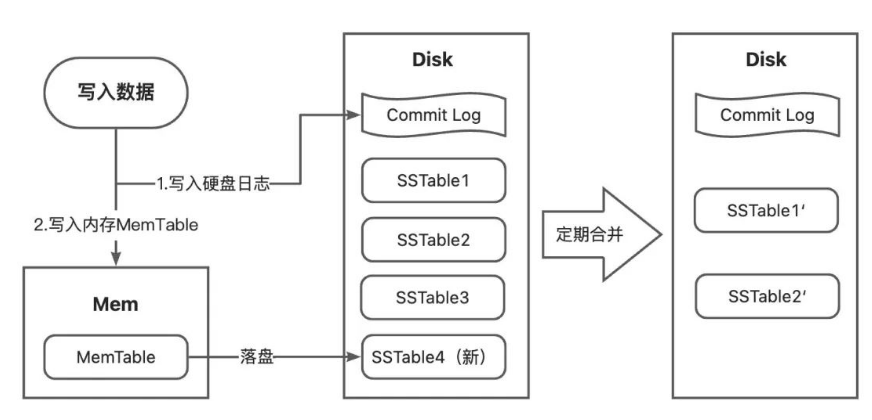
LSM-Tree写入操作分为两步,分别执行,具体步骤如下:
- 第一步为写入操作
- 写入日志文件(Write-Ahead Log, WAL):当有新的 key-value需要写入时,首先将其追加到顺序写的日志文件中。这个操作称为预写日志(Write-Ahead Logging),它可以确保数据的持久性和一致性。
- 写入内存缓存(MemTable):同时将新的 key-value写入内存中的数据结构,通常是跳表或红黑树等有序数据结构。内存缓存可以快速响应读取操作,并且具有较高的写入性能。
- 第二步为定期合并
- 内存与磁盘的合并(MemTable to SSTable):当内存缓存达到一定大小或者其他触发条件满足时,将内存缓存中的 key-value写入到磁盘上的 SSTable 文件中。即在MemTable满时将其转为Immutable MemTable,同时构建新的MemTable,保证向内存写MemTable和向磁盘写新的SSTable可以同时进行。
- SSTable的合并:当SSTable数量到达阈值时,进行合并。合并操作将多个 SSTable文件进行合并,消除重复的 key和删除的 key,并生成新的 SSTable文件。合并操作可以基于时间、文件大小或其他条件进行触发和控制。
LSM-Tree的一些特性:在执行Update和Delete操作时并不会真正去操作SSTable中的数据,如果在MemTable中已有记录则直接执行修改操作(用新的覆盖旧的),否则直接写入,有点类似于追加写入。由于读取时自上而下读取,自然会先读取到新的数据。在进行SSTable合并时也是利用时间戳去进行操作。
可以从下面这张图直观感受LSM-Tree写入过程:
LSM-Tree查找
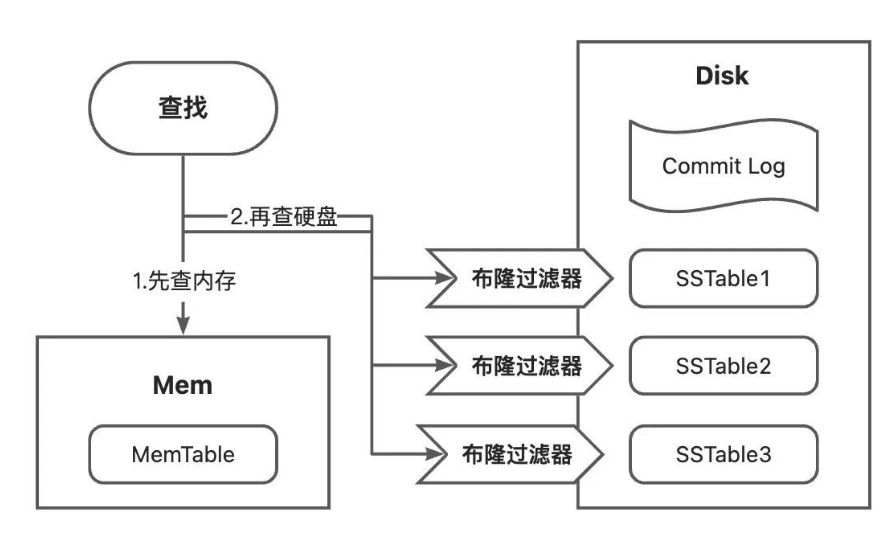
LSM-Tree的查找分为三步,首先是查找内存,不中再查硬盘,具体步骤如下所示;
- 先查内存中的MemTable,如果命中则返回;
- 再查Immutable MemTable,如果命中则返回;
- 最后查硬盘,依次从 L0 层的 SSTable 文件开始,逐层遍历。首先对每个SSTable对应的布隆过滤器进行过滤,如果判定为在该SSTable中,则查询该SSTable的索引表,索引表key有序,所以是二分查找。如果找到对应的key,则根据偏移值获取数据返回;如果未找到对应的key,则对下一个SSTable重复该过程。
三大组件
MemTable
MemTable是内存中的数据结构,存储近期更新的记录值,因此可以采用一些有序集合来存储,比如跳表、红黑树都是非常不错的选择,整体来说,MemTable相对比较简单,采用的数据结构也比较常见。
Immutable MemTable
Immutable MemTable,可以理解成不可变表。它是因MemTable存储容量达到阈值后转变而来,所以采用的数据结构和MemTable一样。引入Immutable MemTable作为一种中间结构,避免 MemTable的读写冲突竞争,保证对MemTable的写入和向磁盘写入SSTable同时进行,从而提高系统性能。
SSTable
SSTable 是 LSM-Tree 的核心,主要是用于数据在磁盘上的持久化存储,存储一些按照 key 有序排列的键值对组成的 segment。另外,为了加快查询速度,通常需要给 SSTable 创建索引,索引存储在 SSTable的尾部,用于帮助快速查找特定的 segment。索引表在我们操作系统非常常见,像文件管理和存储中都用到了索引表。类似于我们操作系统中的索引表,SSTable也用一张存储表记录了SSTable存储的每个元素的位置。引入索引表后,当从SSTable中取数据的时候,不用把整个SSTable读进内存了,而是只需要读进非常小的索引表即可,极大减少了IO成本。同时索引的key是有序的,所以查找时二分查找方式也非常快。
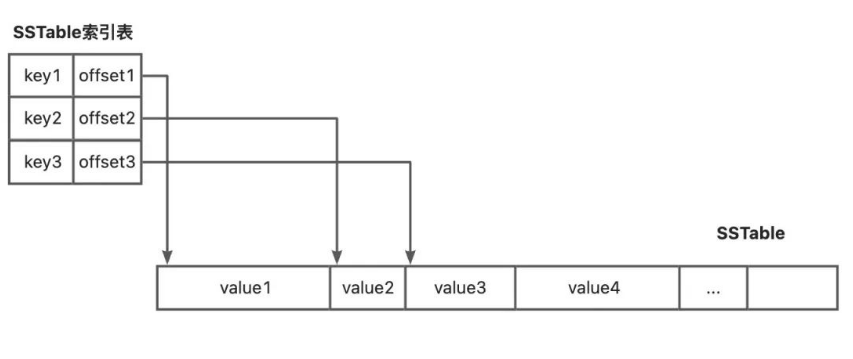
布隆过滤器
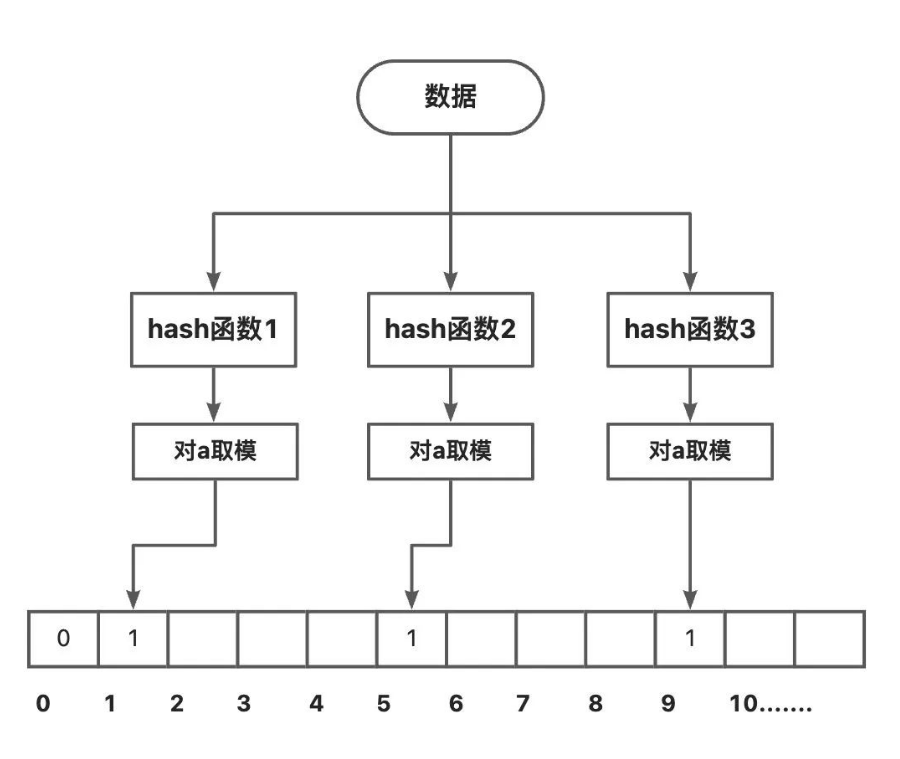
为了进一步减少数据查询时的磁盘IO和提高查询速度,LSM-Tree引入了布隆过滤器。利用布隆过滤器,对所要查询的数据进行一个初步判读。每个SSTable都有个布隆过滤器,如果布隆过滤器判定为没有,则改SSTable中一定不存在改数据;如果布隆过滤器判定为有,则改数据很可能存在于该SSTable中,这是再将索引表加载进内存,进行进一步的查找确认。如果找到则返回;如果未找到,则再匹配下一个SSTable的布隆过滤器。
布隆过滤器结构如下所示:
LSM-Tree优点与缺点
优点:写入快(增、删、改速度非常快),写吞吐量极大:写入时仅写入内存和顺序写入磁盘上的日志,不用关心是否写入磁盘。
缺点:
- 查询较慢,相比于B+树,查询速度较慢
- 范围查找能力较差
- 查询不存在的数据会进行全表扫描,非常慢
总结——我的理解
LSM利用内存写入速度远大于磁盘写入和磁盘批量顺序写的速度要远比随机写性能高出很多的特性,设计出这个结构。写入时分别写入MemTable和WAL中,利用红黑树保证MemTable写入时的有序性,同时写入WAL防止内存崩溃。在MemTable满时将其转为Immutable MemTable,同时构建新的MemTable,保证向内存写MemTable和向磁盘写新的SSTable可以同时进行。如此以来,外部向LSM-Tree中写入数据时分为两步,第一步向MemTable写入数据和向WAL写入日志,第二步实际向磁盘写入数据并调整内部多级Level SSTable,如此两步操作大大提高了写入效率。在LSM-Tree中执行读操作时,读取顺序为:MemTable -> Immutable MemTable -> L0 -> … -> LN, 以这种方式逐层向下进行搜索,读取操作有两个特点:其一便是越靠近上层的数据越新,也就是说自上向下读取到的第一个数据便是当前有效数据;其二便是每个SSTable(包括MemTable)内部有序,能够使用二分查找的方式加快搜索效率。但是这种查找方式存在读放大问题,如果数据较旧,读取的层数可能较多,随着层数增加,读的范围会越来越大,导致读取速度降低。如此便有了优化策略——布隆过滤,在向MemTable中写入时,利用哈希表对key进行映射,存在便映射为1,这样在搜索时便可以利用key进行哈希判断是否不存在了(如果为0可以保证肯定不存在,为1可能存在——哈希映射问题),从而加快搜索效率。
写在最后
LSM-Tree的应用还是非常广的,特别是在数据量特别大、写入特别多的数据库中,目前基于LSM实现的数据库有:LevelDB,RocksDB,Hbase,Cassandra,ClinkHouse等。
我目前了解的badger数据库便是使用的是LSM-Tree,但是做了一些优化,将WAl Log改为了Value Log,同时将Key-Value 分离存储。LSM-Tree 里面存储的是一个 Key 以及 Value 的地址,Value 本身以 WAL 方式 append 到 Value Log 文件中。这样做有两个优势:由于 LSM-Tree 做 Compaction 时不需要重写 Value(每个Value大小相同),大大减小了写放大。同时 LSM-Tree 更小,一个 Block 能存储更多的 key,也会相应的降低读放大,能缓存的 Key 以及 Value 地址也更多,缓存命中率更高。
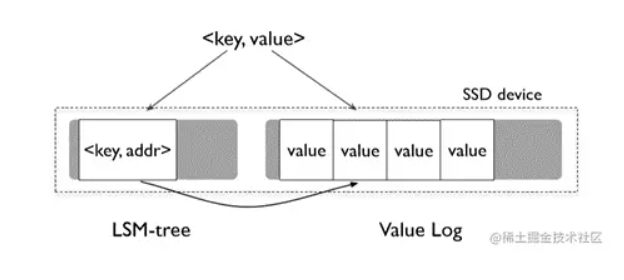
各家数据库优化好像也不太一样,具体我也没多了解,以后有机会会去多学习学习。