bustub项目历程
从去年十月初到今年一月中旬, 历时一个学期, 在实验室的安排下, 着手开始CMU 15445 23fall的数据库知识的学习和Project的实现, 终于是在过年前完成所有的Project。正好寒假在家有时间, 就着手建了一个个人博客, 写一下我在实现Project过程中遇到的问题和收获。关于课程视频, 我时间有限, 且没有太大兴趣, 就只看了前几个视频就没看了, 如果有同学感兴趣的话, 还是推荐看一下, 理论知识的学习还是很重要滴。
前言
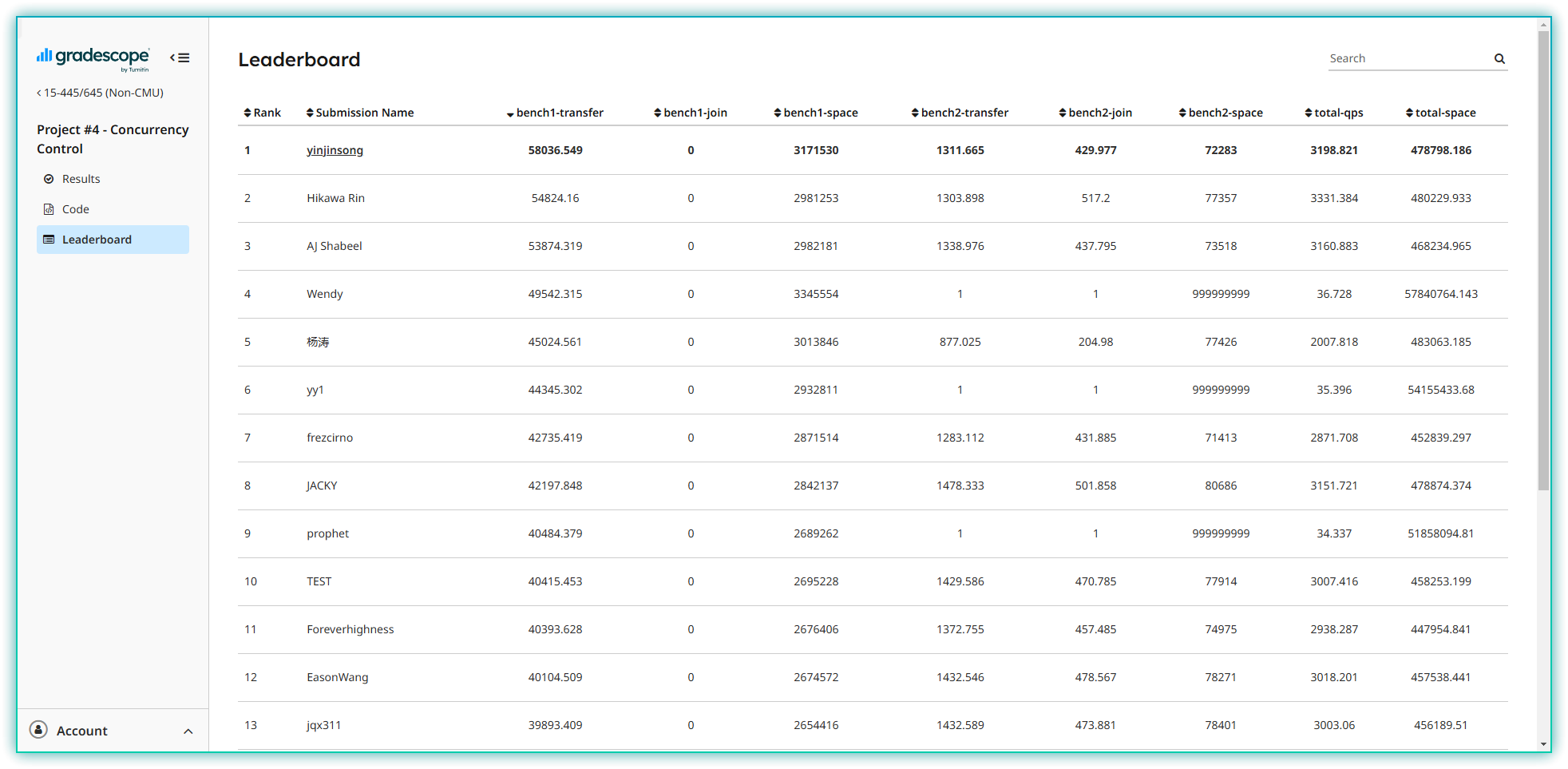
老规矩,先看一下最终排名,截止2025/02/10, 总分第7,单榜第1,打开LeaderBoard第一个就是我了(嘿嘿)
个人认为project4完全做完应该是4个project中最难的吧,花的时间是最多的,不过开始写的时候刚好考试比较多,没多少时间写,大概花了几天时间把前几个task完成了,最后在考试完后回家写了几天才写完。虽然可能没写太久,但是感觉花费的精力挺多的。最后还是课程中那句话,有空闲时间再写写这个,优先去做更重要的事情。
Project4 项目概述
在本次项目中需要实现数据库中的事务管理部分,也是在p3中介绍的SQL执行过程中开始和结束的部分。开始我们需要实现事务管理器创建事务,watermark对正在运行的事务的时间戳管理——用于垃圾回收,在当前正在运行的事务的时间戳范围之外即是可以回收的事务。再之后就是在事务执行时增删改查以及事务提交部分,由于不同事务创建时间点不同,需要读取不同时间点的数据,所以undoLog版本链由此而生,事务顺着版本链读取自己正在操作的数据或者当前事务创建前的数据(保证访问数据是自己能够访问的),Reconstruction函数也是因此而生的,用于对Tuple顺着版本链回退版本。增删改查操作比较简单,主要是保证读写版本链的正确性,读操作读取到正确的数据,写操作访问合法范围的数据(没有其他事务正在操作或已经操作过)。commit操作主要是修改事务的状态和提交时间戳(后续会用),并且修改事务操作过的数据的时间戳(修改为提交时间,事务操作时为事务id,防止其他事务操作)。垃圾回收就很简单了,回收watermark中时间戳范围外的已提交的事务即可。
然后就是麻烦的部分来了,开始考虑索引的影响,读操作会调用IndexScan(需要修改),Insert时需要考虑索引冲突,Update时需要考虑主键修改。在这之后就是所有的并发,包括插入的并发(需要考虑索引冲突)、更新的并发(这个倒是没有主键更新)、事务取消的并发(bonus中的部分)、序列化的并发(leaderboard-2),并发算是这部分中的难点。总结并发实现就是重构重构重构,改了很多才全部实现通过。
Task #1 - Timestamps
task1主要是熟悉下这部分内容相关代码,写的部分比较简单。总共实现两个部分:
- 事务管理器中创建事务,赋予时间戳,将其放入watermark中
- watermark管理所有正在运行的事务,保存正在运行的事务的最小时间戳,创建事务时向其中添加事务时间戳,提交事务时从中删除。 关于这一部分的O(1)实现方法,利用事务管理器中的last_commit_ts_,它赋予给所有创建的事务,并且是单调递增,在commit时+1。这样便可以确定watermark中时间戳在一定的范围内,时间范围最大为last_commit_ts_,最小为正在运行的事务中的最小时间戳,并且由于时间戳+1递增,所有watermark也使用+1递增寻找符合的事务。具体实现为除非watermark为空,否则添加时不修改watermark值,删除时判断是否还有时间戳为watermark的事务,没有就递增搜索,直到commit_ts。
Task #2 - Storage Format and Sequential Scan
task2算是初步了解这部分中的内容,也是两个部分:
- Tuple Reconstruction,根据undo_logs中内容回退tuple中的数据,主要注意的是对已删除的数据的操作(执行前已删除,执行后已删除)
- 顺序扫描,顺着版本链扫描,如果为当前事务操作的数据或者时间戳比当前事务创建时间戳小,直接读取即可,对于其他事务正在操作或已经操作过的数据,需要顺着undo_log版本链构建undologs,使用1中的函数构建合适的Tuple
Task #3 - MVCC Executors
task3算是这部分的核心内容吧,实现增删改查这些基本操作在事务下的执行过程以及事务的提交,
Insert
向table中插入数据即可,需要同时向write_set中传入对应rid(后续会在commit中统一修改对应Tuple的时间戳,表明该Tuple没有事务在执行,当前事务操作完毕,也可以用于Abort中取消对Tuple的操作)
Commit
commit主要是两个操作,一是修改last_commit_ts_以及当前事务的commit_ts;二就是读取write_set,修改事务执行过写操作的Tuple的时间戳为当前事务提交的时间戳即commit_ts
Update && Delete
Update和Delete操作差不多,都是根据读取的数据进行操作,需要判断读取的数据时间戳,有三种情况:
- Tuple时间戳小于等于当前事务时间戳,表明这个Tuple没有被当前事务之后的事务操作或正在被其他事务操作,直接操作Tuple,然后写入UndoLog、写入writeSet、更新VersionLink
- Tuple的时间戳等于当前事务ID,表明这个事务之前被当前事务操作过,在操作过Tuple就需要更新之前提交的UndoLog
- 其他情况,包括没有事务操作但时间戳比当前事务操作(被当前事务之后的事务操作过了)、已经有其他事务在操作了两种情况,这两种情况都是写写冲突
Stop-the-world Garbage Collection
垃圾回收实现比较简单,主要是利用task1中的watermark来实现,对于所有已提交的事务,如果它的提交时间比watermark_ts小或者undo_log为空,这两种情况都表明这个事务都不再被访问,直接回收即可,总共就一个循环加上一个判断即可,没几行代码。这里解释下为啥这样写,一是watermark本来就是为了垃圾回收机制而设计的(我是这样理解的),二是对于所有undoLog为空的事务,不会有版本回退访问到的情况,三就是对于所有提交时间戳小于watermark的事务,是不会被正在运行的事务访问到的,仔细想一想,undoLog是存放修改之前的数据状态。
Task #4 - Primary Key Index
task4中引入索引,不过是单索引,这时候对版本链的操作发生了变化。由于索引指向的地址不会发生变化,对于同一个索引指向的Tuple存在删除数据后又重新插入的情况,同时在插入时要需要判断索引冲突。引入了索引版本链才算完整(从Reconstruction的操作来看,存在从删除状态到未删除状态),同时索引在创建后是不会被删除的。这部分就和project3的多索引部分冲突了,因为可扩展哈希不支持多索引指向同一个Tuple,所有Project4和Project3不兼容。其实底层实现也有冲突,Project3更新操作是删除原数据,创建新的Tuple,因为Tuple大小不固定,但是在Project4就是原地修改,这时Tuple的大小就是固定了,这里可能存在冲突,不过我也没有去细看过,因为前面部分就冲突了,哈哈。
Inserts
这一部分便是重构Insert,考虑存在索引的情况。大致介绍下我的实现(包括并发):
- 首先便是判断是否有索引冲突,有就直接报写写冲突即可,同时记录插入的Tuple的索引是否存在
- 如果对应的索引存在,依旧是判断是否存在写写冲突,即索引指向位置的Tuple是否已删除且没有其他事务正在操作,满足条件就直接插入即可,修改versionLink、UndoLog、以及writeSet
- 如果对应的索引不存在,那么就和原本的Insert一样,插入数据,更新VersionLink(第一次插入是没有undoLog),然后创建对应索引即可
- 介绍下我对插入并发的实现,在1中判断是否有索引冲突,防止已经有索引还插入,在3中进行索引创建检查冲突,这里便是并发关键,如果有多个指向同一个索引的Tuple插入,便会发生竞争插入,最终只有一个插入成功,其余全部失败。
Index Scan, Deletes and Updates
这里是task中最麻烦的一部分吧,还有个Update的并发,介绍下我的实现。
- 由于引入了索引,所以根据project3中实现的优化,这里会调用IndexScan,所以需要修改IndexScan,使其能够适应事务的操作,实现大致和SeqScan差不多吧
- Delete和Update操作没有太大变化,主要是由于索引存在,版本链和之前不同,存在对已删除的地方进行插入,所以对undoLog和versionLink的操作有小部分修改
- 最后介绍下并发的实现,并发使用versionLink来实现并发操作。先介绍下原理,实现的关键是UpdateVersionLink和GetVersionLink函数中有锁,并且这个函数由txn_manager管理,保证所有事务对versionLink的操作是原子的(原子操作是实现并发的关键,加锁便是为了实现原子操作——执行过程不会被其他事务插队)。接下来就有点类似于操作系统中的利用底层原子操作来实现并发的方法了——自旋检查,检查过程是原子的,通过这部分实现并发。下面是具体实现(也是借鉴了其他实现了这部分代码的大佬的思路):
- 先检查写写冲突,有写写冲突直接退出即可
- 自旋检查version_link中in_progress是否为false,这表明这个rid指向的tuple没有其他事务在操作
- 调用UpdateVersionLink函数,传入检查函数,检查是否已经有其他事务获取了in_progress(检查是原子的),然后修改in_progress为true,表明有事务在操作该Tuple,其他事务只能自旋等待。如果执行失败可以跳转1重新检查并进入自旋等待
- 再次检查是否有写写冲突(这部分貌似没有被执行过,在我的代码里我测过,不过其他大佬都写了,我也写一下)
- 写一下我的微操作,也是其他大佬没写的部分。一是修改了VersionLink的状态,在原本的设计中,在最开始插入时,versionLink是为空的,但是这样自旋判断存在问题(没有versionLink,就没有in_progress),所以我在一开始就插入versionLink,让它指向一个不存在UndoLog(默认的),通过GetUndoLogOptional函数来判断是否到版本链终点,这其实也是我最开始写这部分的想法(让versionLink——指针指向为空表示没有UndoLog,而不是UndoLog指向为空),也和其他同学交流过,终于这样写也是舒服了。二就是在commit时在统一修改versionLink的in_progress为true,这样也和write_set同步了,也不需要加入多的结构,正好符合设计,也防止被其他事务插队。
Primary Key Updates
主键更新也是大坑,倒是没有并发,但是是单索引,不符合Project3的测试。实现的关键点就是先获取所有的数据,对其进行更新操作,判断是否有索引冲突,然后再统一删除原本的数据,然后插入新的位置。冲突可以通过Expression中修改的位置下标来判断是否有索引变化。
Bonus
Bonus Task 1: Abort
Abort主要是实现Abort函数,通过writeSet来将事务操作过的数据恢复原本的状态,同时回退versionLink和UndoLog,这部分主要是针对前面写写冲突抛出的tainted的事务,将其所做的操作复原。这部分还有个更重要的问题是并发的实现发生了变化,原本是利用in_progress来实现并发,从这里开始使用底层的page锁来实现并发了,原先的versionLink锁的部分可以删除了,不过并发的实现也变得更简单了。
Bonus Task #2 - Serializable Verification
这一部分主要是检查在事务并发过程中,是否存在并发过程中事务执行顺序不同导致不同的结果——即序列化的正确性,如果存在这种情况,就需要进行Abort。这部分主要是实现VerifyTxn函数,这个函数主要是检查已经提交的事务中是否存在和当前事务有序列化冲突的情况,如果有便直接Abort,这个已经提交的事务是指当前事务执行过程中可能会对当前事务操作的数据进行影响的事务,即提交在当前事务创建之后。
leaderboard
LeaderBoard难点在第二个,也就是对 bonus task2 序列化的并发实现,如果有问题,请查看其他代码的实现有无问题,反正就是重构重构。给的论文没有去看,有时间再说吧,感觉直接写就行,也不一定需要看,就像课程内容一样。
写在最后
到此bustub 23fall 的4个project已经圆满完成,所有分数已经拿齐,能做的优化也基本做了,除了project3的LeaderBoard,其他的都做了,也取得了不错的成绩,还是不错的。接下来按照安排是去实现tinykv,可能也会写一写文章吧,还有bustub24fall可能也会去做,稍微瞄了一眼,24fall也改了不少,而且B+树的实现是必须要去做的。总体感觉bustub一年比一年难了,也更加完整了,也是变得越来越好了,希望这门课程变得越来越好吧。通过这4个project也是学到了很多东西,对C++、对数据库、对代码能力都是巨大的提升,有兴趣的同学都可以来写一写(不过看到这的同学都是写过的吧,哈哈)还是挺不错的。
最后, 感谢 CMU 15445 的老师和助教们的辛勤付出
考虑到网上实现最后这部分内容的文章比较少,代码也是没有,我把我的代码放在这,这部分课程也是即将结束,应该也没几个人写了,有兴趣的同学可以参考一下。