bustub项目历程
从去年十月初到今年一月中旬, 历时一个学期, 在实验室的安排下, 着手开始CMU 15445 23fall的数据库知识的学习和Project的实现, 终于是在过年前完成所有的Project。正好寒假在家有时间, 就着手建了一个个人博客, 写一下我在实现Project过程中遇到的问题和收获。关于课程视频, 我时间有限, 且没有太大兴趣, 就只看了前几个视频就没看了, 如果有同学感兴趣的话, 还是推荐看一下, 理论知识的学习还是很重要滴。
前言
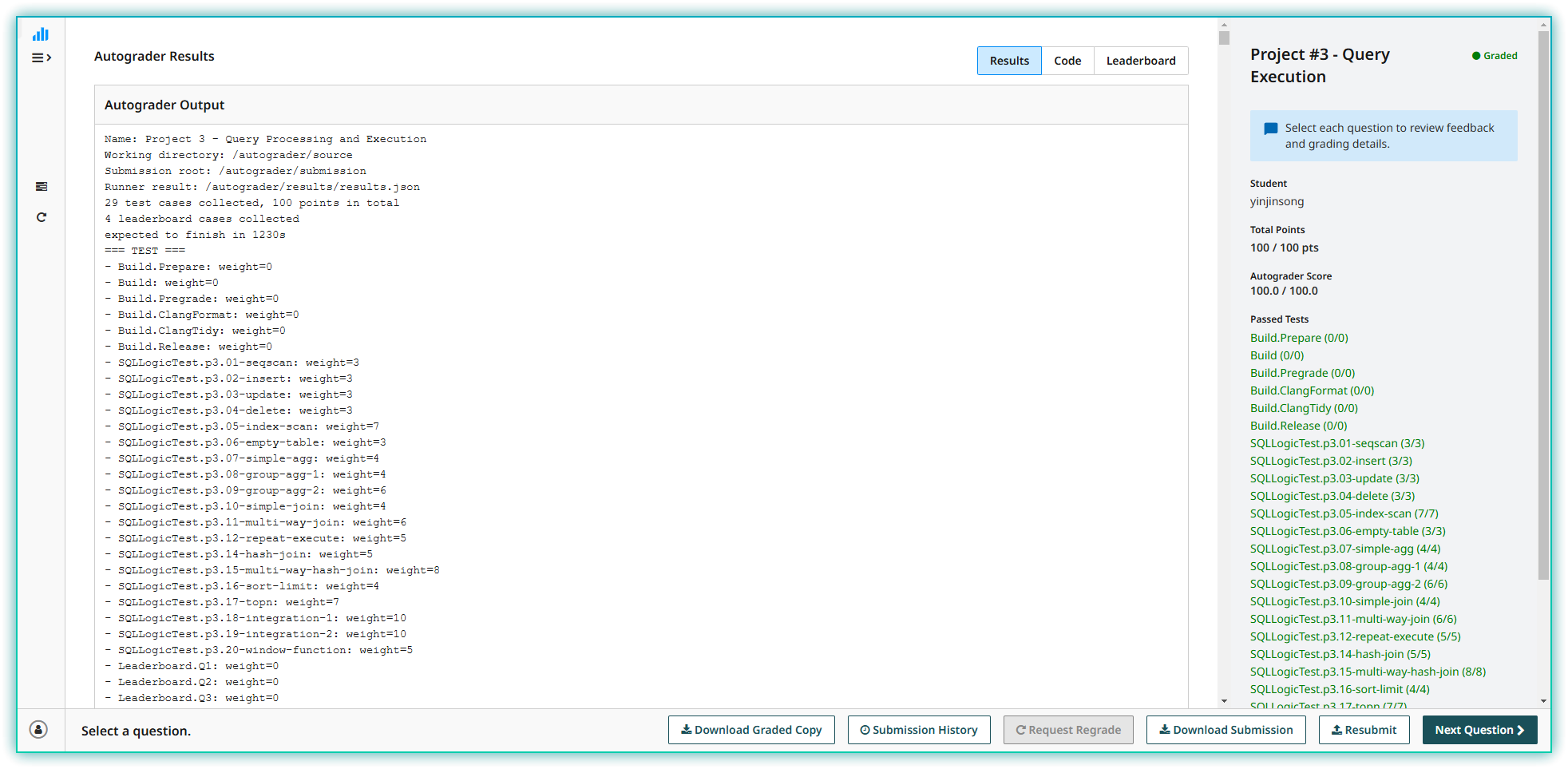
project3开始真正进入数据库的实现了,通过实现这一部分内容,你会对数据库的基本结构有一个清晰的认识,在这一部分中需要多读代码,具体实现较为简单,需要对数据库的整体实现结构有一个清晰的认识才好实现这一部分内容。这一部分的leaderboard我没有做,感觉设计不是很好,不太感兴趣,就没写这部分,看榜单也没几个人写这个,我这里就放一下100分的截图。
Project3 总体概述
这里介绍下我对下面这个整体流程图的认识:首先由事务管理器创建事务,然后由事务执行SQL语句,然后开始解析SQL语句(Parser)(在bustub_instance中),根据解析出来的语句与相应的关键字进行绑定(Binder),然后构建出执行树(Planner),再之后对语法树进行优化(Optimizer)(调整结构,在bustub中是逻辑优化,安装固定顺序执行设定好的优化)。语法树优化完毕后便将其传递到执行器中执行(Executor)(包含执行的上下文即事务、相关数据如索引表、table表,Expression如where表达式中的谓词),执行器使用火山模型,自底向上分层执行,上层调用下层获取执行结果,并将本层的执行结果传递给更上层。火山模型优点挺多,设计简单,各层解耦合,执行效率也比较高。

总体来说,这一章并不难,关键在于与前面两章完全解耦(前面两章为索引和底层的缓冲池,索引和表都在用),在本章中需要阅读大量代码,对整个项目有一个基本的认识,才能够着手开始实现执行器和优化器中的业务逻辑,业务逻辑实现并不复杂,关键还是读代码学习简易数据库的设计。
Task #1 - Access Method Executors
task1就是实现基本的增删改查的内容,关键是需要理解数据库的整体设计,如表的设计、索引的使用(project2中设计),二者关联、Expression的使用,执行计划树结构,以及火山模型的执行器设计结构。还需要对常用结构有清楚的认识,如index索引、table表数据、schema表数据与索引的关联、plan可能会存放的数据(如操作的表id,涉及到的Expression),以及Expression的Evaluate操作(常量表达式、逻辑运算、比较运算、算术运算、字符串)
优化操作,将顺序扫描优化成索引扫描,具体是否优化看where表达式中的谓词,实现细节仿照已有的优化器即可(自带几个实现好的优化器)
Task #2 - Aggregation & Join Executors
Aggregation
聚合操作,即一些分块(group by)函数(如min、max、avg、sum)操作,关键点在于需要实现一个自定义的哈希表,根据groupby结果生成对应的key,并对key值对应的value执行指定的聚合操作。按照这些操作形成聚合树后再就行迭代访问得到结果即可。
NestedLoopJoin
联结操作,即多表联结,主要就是对两表进行联结操作,保留左表和右表,两重循环表里左表和右表(左表在外层),符合条件的即为联结的结果
Task #3 - HashJoin Executor and Optimization
HashJoin
仿照实现一个类似于Aggregation中的自定义哈希表,将原本的NLJ为两层循环操作,通过哈希表,将内层变成哈希表查找符合条件的元素,将两层循环便优化成一层循环,时间复杂度由O(n2)优化成O(n)
NLJ -> HashJoin
根据Expression中的逻辑表达式进行递归判断即可,在执行时需要根据col_id判断是左表还是右表的数据,将其放入正确的位置
Task #4: Sort + Limit Executors + Window Functions + Top-N Optimization
Sort & Limit
最简单的一集,sort实现一个自定义的排序逻辑传入std::sort调用即可,limit就更简单了,取前几个数即可
Sort & Limit -> Top-N
先排序再取前几个数,也很简单,无非不是把limit和sort结合,优化就是看看执行树中是否有相邻两层为Limit和Sort
Window Functions
WindowFunction是project3中最难的一部分了吧(除去LeaderBoard部分),需要根据是否有orderBy来进行排序(但是只需要排序一次), 使用partition来进行分类,然后进行函数操作,这部分有点类似于Aggregation操作,分类以及函数操作,只不过多了一个rank(需要单独考虑)
写在最后
project3难点还是在于读代码,了解整个项目的设计结构,具体实现也就是一些常用的执行器的实现以及实现了几个优化器,但是也并不难。整体来说还是收获到很多东西,这一部分可能写的不是很详细,一是时间已经过去很久了,记不太清了,二是在后续project4中会修改很多地方,导致代码已经变化很多了。