bustub项目历程
从去年十月初到今年一月中旬, 历时一个学期, 在实验室的安排下, 着手开始CMU 15445 23fall的数据库知识的学习和Project的实现, 终于是在过年前完成所有的Project。正好寒假在家有时间, 就着手建了一个个人博客, 写一下我在实现Project过程中遇到的问题和收获。关于课程视频, 我时间有限, 且没有太大兴趣, 就只看了前几个视频就没看了, 如果有同学感兴趣的话, 还是推荐看一下, 理论知识的学习还是很重要滴。
前言
Project2开始涉及到数据库索引的底层实现,今年做的是可扩展哈希,相比于B+树要简单不少,推荐学有余力的同学去做一下其他年份的B+树,总体来说没做多久,比Project1花的时间稍多一点。然后说一下LeaderBoard结果吧,截止2025/01/30排名第6
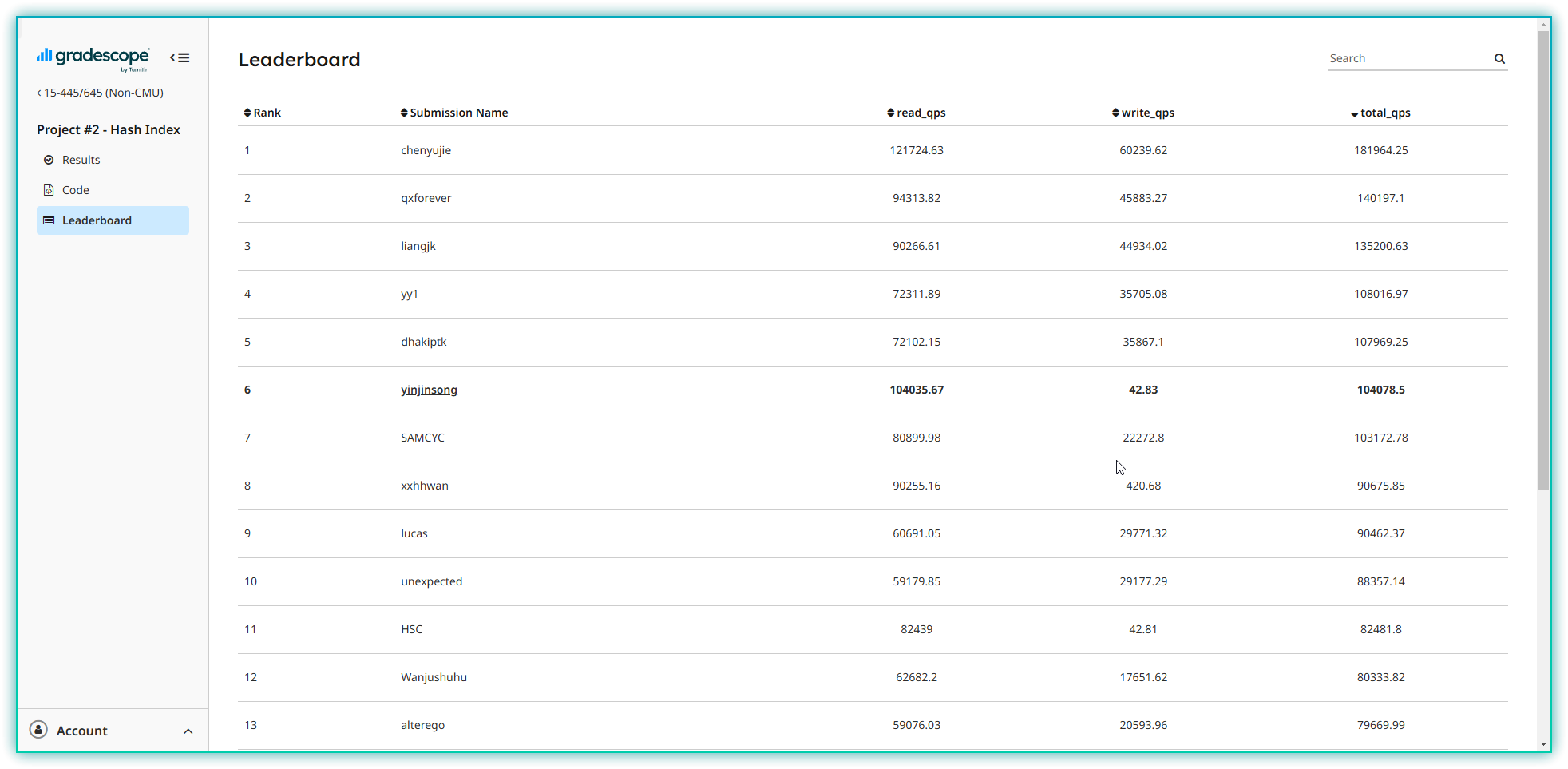
时间有点久远,实现细节基本都忘了,讲一下我的整体思路吧
Task #1 - Read/Write Page Guards
Task1中实现对Page的读写锁的析构时自动释放和调用函数手动释放操作(要实现的就是一个能够在生命周期结束时自动释放锁和手动释放锁的结构),这部分实现较简单
- BasicPageGuard、ReadPageGuard、WritePageGuard类的构造函数、析构函数、=重载函数、Drop函数的实现,需要注意的是对锁不能重复释放,需要先进行判断
- bufferPoolManager中pageGuard获取函数实现,锁在ReadPageGuard、WritePageGuard外部获取,但是在内部释放,感觉设计挺奇怪的,导致我一开始写这一部分出了些错误,后来想其觉得设计还是挺奇怪的,个人认为把锁的获取放在构造函数内更优雅
Task #2 - Extendible Hash Table Pages
这部分实现可扩展哈希的三层结构的具体实现,包括初始化,各种功能函数的实现,基本按照函数名就知道有啥用,相应实现即可,比较简单。
自底向上简单介绍下这三层结构的意义:
- bucket层,桶的功能设计,实际存放所有的元素,所有的增删改查都会操作这层实例元素,并且所有索引指向的元素是唯一的,插入前需要检查
- directory层,可扩展哈希的核心设计,向下进行桶的分裂与合并(也是这部分的难点),保证存储空间的高效利用,向上提供索引,指向实际元素的位置。
- header层类似于操作系统中多页表设计中的外层页表,用于增加directory的数量和并发度,实现通过索引映射到不同的directory
- 总结,整个可扩展哈希核心便是利用二进制数来进行索引,通过将二进制数不同段分别用于各层中的指向,实现了树形的索引树,同时在最下面两层,利用桶的分裂合并极大提高了空间效率。
- 关于桶分裂合并提高空间效率,通过利用global_depth_, local_depth_ 字段,将二进制中低位用于指向不同的bucket,高位用于重复利用,实现多个索引指向同一个桶,同时利用二进制位运算的性质,使得桶的分裂与合并操作较为简单。
- 多层的设计也是提高了空间利用率,在可扩展哈希的设计中,加锁只需要控制住两层即可,也就是说不同的directory之间是可以并发的
- 整个设计类似于多层哈希设计,不过通过利用二进制数来充当索引,同时利用了桶的分裂合并提高了空间效率。但是本身存在不少问题,包括并发度不高,并且索引冲突的问题无法解决。由此来看,如果想要深入学习数据库,学习B+树还是必要的,可扩展哈希貌似用的也不多,也没啥可优化的
Task #3 - Extendible Hashing Implementation
大致讲下这几个函数的实现思路:
- GetValue,也即是读操作,根据生成的索引从header(根节点)向下搜索直到得到对应节点退出,或者对应节点不存在返回false
- Insert,向内存中写入数据,根据索引向下进行搜索对应节点位置,如果不存在则创建(directory、bucket),如果重复则直接退出即可。关键便在于如果插入的桶满了,这时候需要进行桶的分裂操作
- 如果global_depth与local_depth相同,表明全局深度与局部深度相同,这时候就需要增加global_depth,增加bucket个数。
- 否则进行bucket分裂即可,分裂即增加local_depth,修改所有影响的bucket(用对应bucket复制即可)
- 分裂完毕重新进行插入操作,有可能插入失败(由于是按照索引来存放的,分裂后可能还是桶满),所以需要循环进行,直到达到最大深度或者插入成功,否则即插入失败
- Remove,删除内存中的数据,由索引向下搜索,搜索到删除即可,搜索不到则说明不存在,返回false。关键是在删除后如果bucket为空,需要进行桶合并
- 桶合并需要使用位运算,判断local_depth下所有的桶都能够进行合并,否则如果存在不能够合并的桶,则不能进行合并操作。本质上是使用位运算来进行操作,local_depth决定取的低位数(即合并后的桶),左侧没取到的是高位数,左侧变化所包含的所有需要合并的桶的深度必须相同,才能够保证能够进行合并。
- 和桶分裂相同,桶合并操作也需要循环进行,直到不能够进行桶合并为止(存在合并一次后还能够合并)
写在最后
可扩展哈希实现还是挺有意思的,但是可扩展哈希局限性太多,也没啥可优化的,相比之下B+树应用更多,难度也更大,学有余力的同学还是去学习下B+树的部分。