bustub项目历程
从去年十月初到今年一月中旬, 历时一个学期, 在实验室的安排下, 着手开始CMU 15445 23fall的数据库知识的学习和Project的实现, 终于是在过年前完成所有的Project。正好寒假在家有时间, 就着手建了一个个人博客, 写一下我在实现Project过程中遇到的问题和收获。关于课程视频, 我时间有限, 且没有太大兴趣, 就只看了前几个视频就没看了, 如果有同学感兴趣的话, 还是推荐看一下, 理论知识的学习还是很重要滴。
前言
Project1整体还是比较简单的, 大概在第一周就完成了Project1的全部内容, 然后在Project2完成之后, 花了一周的时间实现了Project1的代码优化。
然后说一下优化结果, LeaderBoard 排名第10(2025/1/27), 优化结果如下:
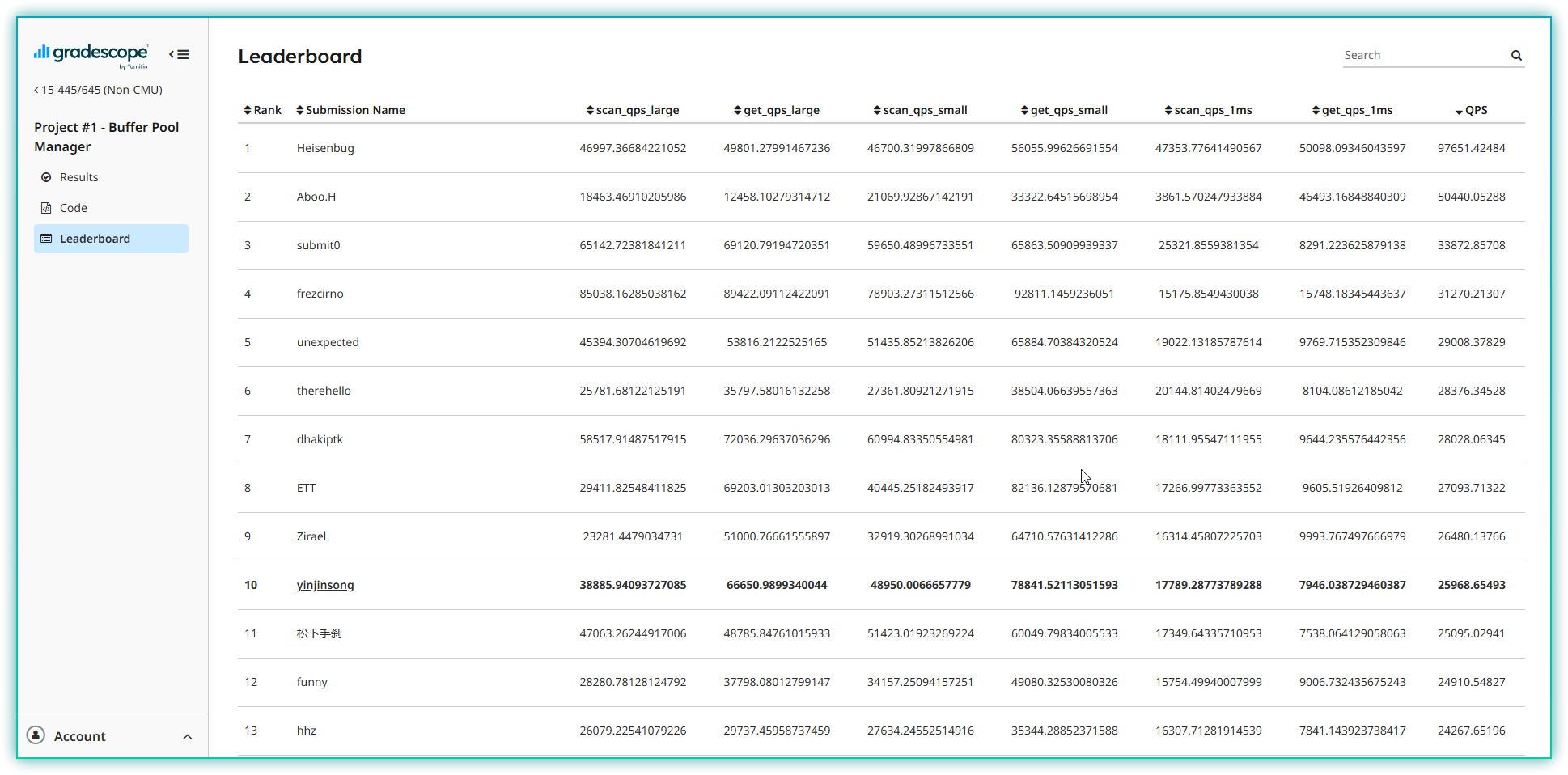
给前面几位神仙跪了, 断层领先, 有理由怀疑在hack, 各项数据太吓人了。我的这个排名差不多就是我的极限了吧, 能做到都已经做了。(hack我也不会, 哈哈)
根据课程要求, 源代码暂时就不公开了, 等23fall课程结束再说吧
Project1 总体概述
在Project1中, 我们需要实现内存中缓冲池管理, 包括lru-k策略(内存调度策略), Disk Scheduler(磁盘调度, 即读写磁盘数据操作), BufferPoolManager(结合内存调度和磁盘读写操作, 实现内存缓冲池管理, 实现读写物理page)。为什么要实现这个Project呢, 学过操作系统的同学应该就知道, 实际的物理存储介质呈金字塔形状, 内存大小远远小于物理磁盘, 内存中的空间是有限的, 要想访问存储在磁盘中的庞大数据, 就需要实现一个内存缓冲池, 将需要使用的页面调度到内存页中, 将不再访问的页面写回到物理磁盘中, 实现好像在读写整个物理磁盘的效果。
Task #1 - LRU-K Replacement Policy
在Task1中我们需要使用lru-k策略实现内存页调度策略。其中每一个frame对应一个内存中的page(数量有限, 内存页), 而在bufferManager中的page是实际存储数据的物理page(物理页), 相对于frame(内存page)而言是无限的。从这里就可以看出, 我们的任务实际是在实现内存的调度策略, 将物理页中的数据调度到内存页中进行访问, 当空闲内存页不够时, 对正在使用的内存页进行Evict, 获取空的内存页, 然后在bufferManager中将新的物理page中的数据存放到内存页中以便访问。
实际实现内容:
- Evict, 从所有正在使用的内存页(evictable)中淘汰出一个空的内存页, 将其返回给bufferPoolManager
- RecordAccess, 访问记录, 用于lru-k策略
- SetEvictable, 根据frame_id将frame设置为evictable状态, 即可以被淘汰
- Remove, 从lru-k队列中删除指定frame_id, 将其设置为空闲状态, 这个函数实际貌似没怎么用过, 个人认为是跟lru-k策略没啥关联, 并且也需要和bufferPoolManager联动, 将空闲frame_id放入BufferPooManager中
我的实现:
- 使用两个队列存放所有使用的frame
- 一个history_list队列, 存放访问次数少于k次的frame, 先进先出策略;
- 一个lru_list队列, 存放所有访问次数大于等于k次的frame, 我的策略是选择Evict时顺序遍历求访问时间最小的frame(也算是一种lru-k策略的优化吧, 对lru_list进行Evict操作为O(n)操作, 对lru_list队列中的frame进行操作为O(1)操作)
- lru-k策略介绍:
- 如果访问次数小于 K次, 那么不作更改, 因为小于 K 频次时 FIFO.
- 如果访问次数等于 K次, 那么将结点从 history_list_ 中移动到 lru_list_ 中.
- 如果访问次数大于 K, 那么逐出结点记录的最早访问记录, 然后再将该结点插入到 lru_list 队列中(按我的实现策略, 任意位置即可)
- 关于并发, 没什么好的思路, 一把大锁即可
Task #2 - Disk Scheduler
在Task2中我们需要实现对磁盘的读写操作(IO操作), 这一部分比较简单
实现内容:
- 主要实现Schedule函数, 将IO操作独立出去, 放在单独的线程中执行IO操作, 并发优化的点也在这一部分
Task #3 - Buffer Pool Manager
在Task中我们就需要综合Task1中的Lru-k内存调度策略和Task2中的磁盘调度实现缓冲池管理, 使缓冲池能够自由访问物理页数据, 实现页面好像直接在读写物理页的, 不需要了解内存页的效果。
实现内容:
- NewPage, 创建一个新的Page物理页
- FetchPage, 读取指定page_id的物理页
- UnPinPage, 当页面使用完毕, 会调用这个函数, 表明正在使用这个页面的人数减一, 当减到0时, 就可以将其设置为Evictable, 即内存调度策略中可以被淘汰的内存页
- FlushPage, 将指定page_id的页面从内存页写回物理页
- FlushAllPage, 将内存中所有页面写回到物理页
- DeletePage, 删除指定page_id的页面, 将其内存页回收为空闲状态放入free_list_, 如何是脏页面就写回磁盘(这三个函数都没怎么用过)
我的实现:
- NewPage函数, 从AllocatePage函数获取page_id, 从free_list获取内存页, 如果free_list为空就需要从使用lru-k策略从内存内Evictable的页面中淘汰出内存页, 如果淘汰出的页面是脏页面还需要写回磁盘, 剩下就是创建新页面, 返回page_id和Page实例
- FetchPage函数, FetchPage和NewPage差不多, 只是FetchPage需要先判断内存中是否有page_id的内存页, 如果没有, 就需要从磁盘中读取到内存中, 读取操作和NewPage差不多, 只是多了读取磁盘数据
- UnpinPage函数, 修改page中的pin_count_和is_dirty_字段即可, 如果pin_count_变成0了, 将其设置为evictable即可, 这个功能较简单
- FlushPage和FlushAllPage差不多, 一个指定page_id, 一个遍历所有内存中的page, 将内存页写回物理页, 调用DiskScheduler即可, 别忘了重置is_dirty状态
- DeletePage函数, 淘汰指定page_id的内存页, 如果还有人员正在使用那是不能删除的哟, 如果是脏页面就将其学会内存, 剩下就是将其使用的资源回收
LeaderBoard Task
借用下隔壁大佬的话
Doing Project without the LeaderBoard is equivalent to playing games without Genshin Impact.
在这个任务中我们需要实现并发操作, 在一开始最好使用一把大锁, 先确定所有实现的函数有没有问题, 然后再考虑细分锁的问题。
我的实现: 一把大锁加上去, 细化放在优化里面讲
代码效率优化(LeaderBoard排名优化)
Task1 LRU-K Replacement Policy 优化
我的尝试:
- 由于在Task1中已经将lru-k策略设计好了, 我尝试使用另一种实现策略。将lru_list队列设置为有序, history_list队列不变, 每次RecordAccess都对lru_list_进行位置调整, 这样Evict效率变为O(1), RecordAccess效率降低, 但是由于lru_list现在有序(可以冒泡移动), 效率不到O(n).但是最终结果表明这样效率并没有提升, 也可能是我实现有问题吧, 有兴趣的同学可以实现, 这部分代码被无语的我删掉了(版本回退消失了)
- 利用access_type属性, 由于在Leaderboard中开启了16个线程, 其中8个随机读写, 8个顺序读写, 可以access_type稍稍调整lru-k的实现策略实现效率提升(这个我使用了, 确实效率提升不少)
Task2 Disk Scheduler 优化
我的尝试:
- 磁盘调度优化显而易见, 原本磁盘调度是单线程, 将其修改为多线程即可
- 由于并发度不同, 磁盘调度我选择设置为动态线程池, 在并发度较低时线程池也较小(开动态线程池貌似也没啥效率提升, 哭, LeaderBoard测试太死了)
Task3 & LeaderBoard 并发优化
我的尝试:
- 刚开始选择为每一个使用的资源设置一个锁, pages设置一个锁的数组(每个page一个锁), 遵守二阶段锁策略, 尽量将各部分加锁部分分离, 使其尽可能并发
- 随着并发的深入学习实现, 理解了这部分并发提升效率的本质: 并发本质是将IO操作并发(这是可以并发的, 和DiskScheduler实现有关), 其他bufferPoolManager属性加一把锁即可, 这部分没有并发可言, 基本所有函数都有在操作。最关键点在于, IO的操作较慢, 需要并发来提升效率, 实际对属性字段操作较快, 并且多个线程都需要操作, 加锁变成单线程即可
- 最终结果: 对pages外的所有数据使用一把大锁latch_, 对Pages_使用锁数组(防止对同一个page操作并发冲突), 遵循二阶段锁策略, 尽量将IO操作和对bpm的字段操作分离开, 分别加锁, 利用IO并发提高效率
写在最后
本来是考虑使用火焰图perf来看那些部分需要优化, 但是在我的设备上总是有问题, 至今没有解决, 最终选择从设计上来思考如何优化。从最终结果来看, 优化的还不错, 学到了挺多东西, 花了我大概一周的时间。如果有同学想优化代码, 可以考虑使用火焰图, 从使用火焰图的同学和师兄的说法来看, 还是不错的。