bustub 项目历程
从去年十月初到今年一月中旬,历时一个学期,在实验室的安排下,着手开始 CMU 15445 23fall 的数据库知识的学习和 Project 的实现,终于在过年前完成所有的 Project。正好寒假在家有时间,就着手建了一个个人博客,写一下我在实现 Project 过程中遇到的问题和收获。关于课程视频,我时间有限,且没有太大兴趣,就只看了前几个视频就没看了,如果有同学感兴趣的话,还是推荐看一下,理论知识的学习还是很重要滴。
前言
Project3 开始真正进入数据库的实现了,通过实现这一部分内容,你会对数据库的基本结构有一个清晰的认识。在这一部分中需要多读代码,具体实现较为简单,需要对数据库的整体实现结构有一个清晰的认识才好实现这一部分内容。这一部分的 leaderboard 我没有做,感觉设计不是很好,不太感兴趣,就没写这部分,看榜单也没几个人写,我这里就放一下 100 分的截图。
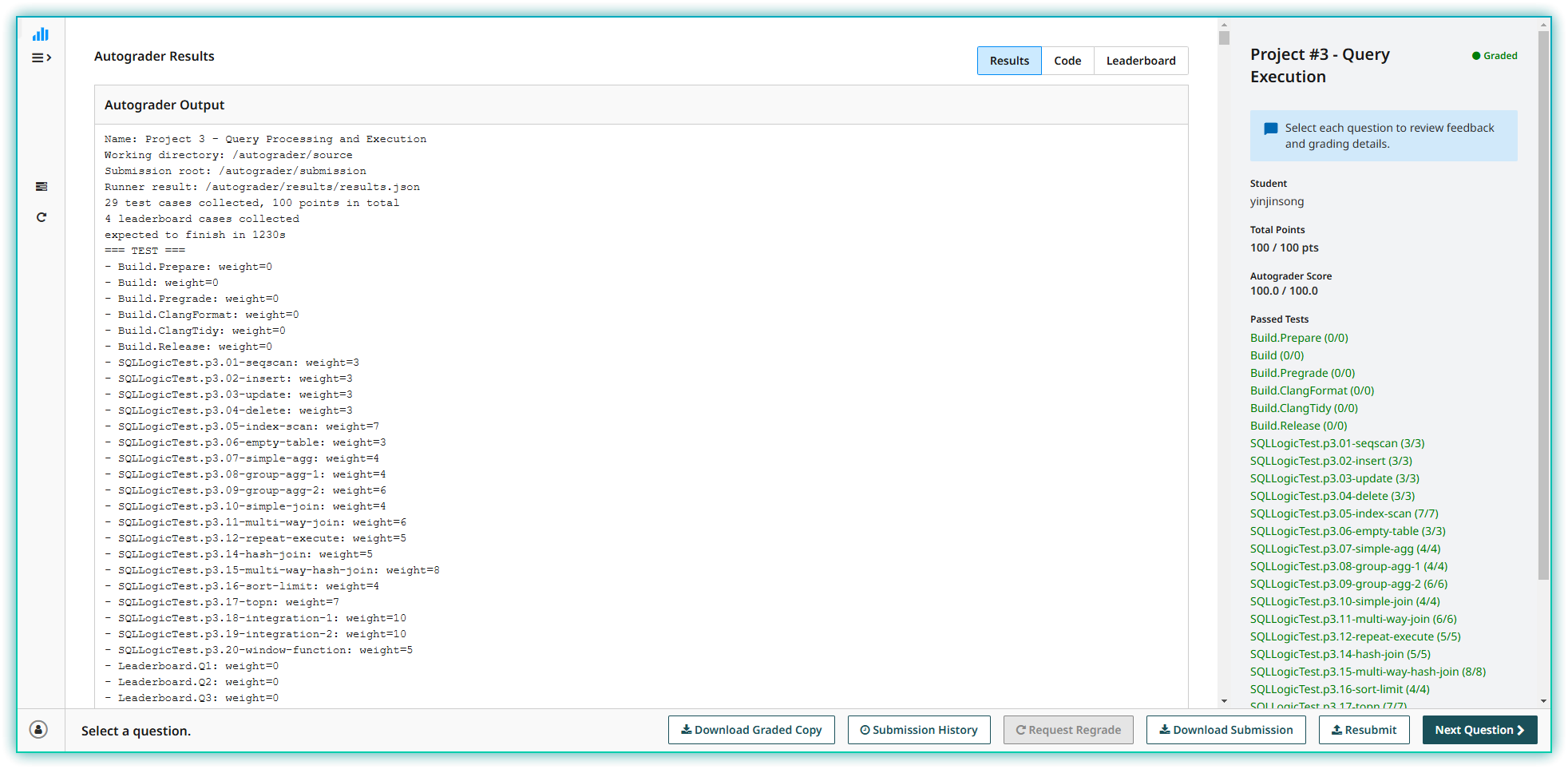
Project3 总体概述
这里介绍下我对整体流程图的认识:首先由事务管理器创建事务,然后由事务执行 SQL 语句,然后开始解析 SQL 语句(Parser,在 bustub_instance 中),根据解析出来的语句与相应的关键字进行绑定(Binder),然后构建出执行树(Planner),再之后对语法树进行优化(Optimizer,调整结构,在 bustub 中是逻辑优化,按照固定顺序执行设定好的优化)。语法树优化完毕后便将其传递到执行器中执行(Executor,包含执行的上下文即事务、相关数据如索引表、table 表,Expression 如 where 表达式中的谓词),执行器使用火山模型,自底向上分层执行,上层调用下层获取执行结果,并将本层的执行结果传递给更上层。火山模型优点挺多,设计简单,各层解耦合,执行效率也比较高。

总体来说,这一章并不难,关键在于与前面两章完全解耦(前面两章为索引和底层的缓冲池,索引和表都在用),在本章中需要阅读大量代码,对整个项目有一个基本的认识,才能够着手开始实现执行器和优化器中的业务逻辑,业务逻辑实现并不复杂,关键还是读代码学习简易数据库的设计。
Task 概览
Project3 共分为四个 Task:
- Task #1 — Access Method Executors:实现基本增删改查,关键是需要理解数据库的整体设计,如表的设计、索引的使用(Project2 中设计),Expression 的使用,执行计划树结构,以及火山模型的执行器设计结构。还包含将顺序扫描优化成索引扫描的优化器规则。
- Task #2 — Aggregation & Join Executors:聚合操作(根据 GROUP BY 结果键对应的 value 执行指定的聚合操作)以及多表联结(NestedLoopJoin)。
- Task #3 — HashJoin Executor and Optimization:通过哈希表将 NLJ 的两层循环优化成一层循环,时间复杂度由 O(n²) 优化成 O(n);并实现 NLJ → HashJoin 的优化器规则。
- Task #4 — Sort + Limit + Window Functions + Top-N Optimization:Sort、Limit、TopN (Sort+Limit 的优化版),以及 Project3 中最难的 Window Functions。
1. 查询处理全链路概览
在 BusTub 中,一条 SQL 语句从输入到输出经历以下完整链路:
SQL 字符串
↓ Parser(词法 + 语法分析)
抽象语法树 AST
↓ Binder(语义绑定,解析表名/列名)
Bound AST(带 Schema 信息)
↓ Planner(生成逻辑计划)
LogicalPlanNode 树
↓ Optimizer(规则/代价优化)
PhysicalPlanNode 树(AbstractPlanNodeRef)
↓ ExecutorFactory(为每个 PlanNode 创建对应 Executor)
Executor 树
↓ 根 Executor 调用 Next(),火山模型驱动执行
结果 Tuples
EXPLAIN 命令可以输出 Optimizer 优化后的物理计划树,是理解执行过程的利器:
EXPLAIN SELECT * FROM t1 WHERE id = 1;
-- 输出类似:
-- === OPTIMIZER ===
-- IndexScan { index_oid=0, filter=... } | (id:INTEGER, val:INTEGER)
2. 火山模型(Volcano / Iterator Model)
2.1 核心思想
火山模型(Volcano Model),也称迭代器模型(Iterator Model),是由 Goetz Graefe 在 1990 年提出的经典查询执行模型。BusTub 的整个执行引擎均基于此模型构建。
核心接口定义在 src/include/execution/executors/abstract_executor.h:
class AbstractExecutor {
public:
explicit AbstractExecutor(ExecutorContext *exec_ctx) : exec_ctx_{exec_ctx} {}
virtual ~AbstractExecutor() = default;
// 必须在 Next() 之前调用,初始化算子(递归初始化子算子)
virtual void Init() = 0;
// 返回下一条 tuple;true = 有数据,false = 数据已耗尽
virtual auto Next(Tuple *tuple, RID *rid) -> bool = 0;
// 返回该算子输出的 Schema
virtual auto GetOutputSchema() const -> const Schema & = 0;
protected:
ExecutorContext *exec_ctx_;
};
整个执行过程是一棵**从根向叶拉取(pull-based)**的调用树:
根节点 ProjectionExecutor
↑ Next() — 拉取下一条 tuple
↓ 调用子算子 Next()
FilterExecutor
↑ Next()
↓ 调用子算子 Next()
SeqScanExecutor
↑ Next()
↓ 读取 TableHeap
TableHeap / BufferPool
2.2 执行流程图解
用户发起查询
│
▼
ExecutorEngine::Execute(plan)
│
├─ ExecutorFactory::CreateExecutor(plan) // 递归创建 Executor 树
│
├─ root_executor->Init() // 递归初始化
│
└─ while (root_executor->Next(&tuple, &rid)):
results.push_back(tuple)
2.3 火山模型的优点
- 实现简洁:每个算子只需实现
Init()和Next(),算子之间完全解耦 - 内存效率高:每次只在管道中传递一条 tuple,内存占用低
- 提前终止:
LIMIT N只需拉取 N 条即可停止,无需扫描全表 - 组合灵活:任何算子都可以作为另一个算子的子算子,形成任意深度的执行树
2.4 火山模型的缺点(重要面试点)
- 大量虚函数调用:每输出一条 tuple 就调用一次
Next(),若表有 1 亿行,则有 1 亿次虚函数调用,CPU 分支预测器难以预测目标地址 - 无法 SIMD 向量化:SIMD 指令要求数据批量连续处理,one-tuple-at-a-time 的模型天然与此冲突
- CPU 缓存利用率低:每次
Next()跨越多个算子,破坏了数据的局部性 - 无法 JIT 优化:表达式求值(
Evaluate())是运行时多态调用,无法被编译器内联
2.5 替代模型对比
| 模型 | 粒度 | 优势 | 代表系统 |
|---|---|---|---|
| 火山模型 (Iterator) | 一次一 tuple | 实现简单,内存效率高 | BusTub, PostgreSQL, MySQL |
| 向量化模型 (Vectorized) | 一次一批(1024~8192 行) | SIMD 友好,缓存利用率高 | DuckDB, VectorWise, Snowflake |
| 编译执行 (Compilation) | JIT 为特化机器码 | 消除所有虚函数开销,极致性能 | HyPer, Umbra, SingleStore |
| 推送模型 (Push-based) | 一次一 tuple(反转控制流) | 代码局部性好,Pipeline 友好 | Noisepage |
向量化模型的核心改进: 批量处理消除大部分虚函数调用(从 N 次降至 N/batch_size 次),且批量数据可利用 SIMD 指令(如 AVX-512 可同时处理 16 个 int32)。DuckDB 的实测表明,对于分析型查询,向量化比火山模型快 10-100 倍。
3. 执行引擎核心架构
3.1 PlanNode 与 Executor 的职责分离
BusTub 严格将逻辑计划(PlanNode)与物理执行(Executor)分离,这是典型的策略模式应用:
AbstractPlanNode(只描述"做什么")
├─ 持有 output_schema_(输出 Schema)
├─ 持有 children_(子计划节点)
└─ 只含元数据,不执行任何 I/O
AbstractExecutor(实际执行"怎么做")
├─ 持有 PlanNode 指针(读取计划参数)
├─ 持有 child executors(递归执行)
└─ 实际操作 TableHeap、Index、Buffer Pool
AbstractPlanNode 定义在 src/include/execution/plans/abstract_plan.h,支持的计划类型(PlanType 枚举)包含:
enum class PlanType {
SeqScan, IndexScan, Insert, Update, Delete,
Aggregation, Limit, NestedLoopJoin, NestedIndexJoin,
HashJoin, Filter, Values, Projection, Sort,
TopN, TopNPerGroup, MockScan, InitCheck, Window
};
分离的好处:
- 优化器只变换 PlanNode 树,不触碰 Executor,两者独立演进
- 同一个 PlanNode 类型可以有多种 Executor 实现(如:未来可以为不同硬件提供 CPU/GPU 版本)
- PlanNode 的
ToString()和EXPLAIN输出方便调试
3.2 ExecutorContext — 执行上下文
每个 Executor 通过 ExecutorContext* 访问全部系统资源:
class ExecutorContext {
public:
auto GetCatalog() -> Catalog *; // 系统目录(表/索引元数据)
auto GetTransaction() -> Transaction *; // 当前事务
auto GetTransactionManager() -> TransactionManager *; // MVCC 事务管理
auto GetBufferPoolManager() -> BufferPoolManager *; // 缓冲池
auto GetLockManager() -> LockManager *; // 锁管理器(2PL)
};
设计意图: Executor 不直接持有这些组件的指针,而是通过 Context 统一获取,符合**依赖注入(Dependency Injection)**原则,便于测试时替换 mock 对象。
3.3 ExecutorFactory — 工厂模式
ExecutorFactory::CreateExecutor() 根据 PlanNode 类型递归创建整个 Executor 树,典型的工厂方法模式:
auto ExecutorFactory::CreateExecutor(ExecutorContext *exec_ctx,
const AbstractPlanNodeRef &plan)
-> std::unique_ptr<AbstractExecutor> {
switch (plan->GetType()) {
case PlanType::SeqScan:
return std::make_unique<SeqScanExecutor>(exec_ctx, ...);
case PlanType::HashJoin: {
auto left = CreateExecutor(exec_ctx, plan->GetChildAt(0)); // 递归
auto right = CreateExecutor(exec_ctx, plan->GetChildAt(1));
return std::make_unique<HashJoinExecutor>(exec_ctx, ..., std::move(left), std::move(right));
}
// ...
}
}
3.4 Tuple 与 Schema
Tuple 是数据在执行层的基本单位:
Schema: (id:INTEGER, name:VARCHAR(32), age:INTEGER)
Tuple: [4字节: id值] [变长: name值] [4字节: age值]
Tuple::GetValue(schema, col_idx)— 获取第col_idx列的值Tuple(values, schema)— 从 Value 数组构造 Tuple- 每个 Tuple 有对应的
RID (page_id, slot_num),唯一标识其在 TableHeap 中的位置
Schema 描述 Tuple 的结构:
class Schema {
std::vector<Column> columns_; // 每列的名称、类型、偏移量
static auto CopySchema(const Schema *from, const std::vector<uint32_t> &attrs) -> Schema;
};
Schema::CopySchema() 在 MVCC undo log 记录中频繁使用,用于创建只包含"修改过的列"的子 Schema(稀疏存储优化)。
4. Access Method Executors — 数据读写算子
4.1 SeqScanExecutor
文件: src/execution/seq_scan_executor.cpp
SeqScan 是最基础的数据访问算子,顺序扫描整张表。
4.1.1 核心实现
void SeqScanExecutor::Init() {
// 创建 TableHeap 迭代器
table_iterator_ = std::make_unique<TableIterator>(
exec_ctx_->GetCatalog()->GetTable(plan_->GetTableOid())->table_->MakeIterator());
}
auto SeqScanExecutor::Next(Tuple *tuple, RID *rid) -> bool {
// 循环直到找到一条对当前事务可见的有效 tuple
while (!table_iterator_->IsEnd()) {
*rid = table_iterator_->GetRID();
// 加表页读锁
auto page_guard = table_info->table_->AcquireTablePageReadLock(*rid);
auto page = page_guard.As<TablePage>();
auto [tuple_meta, tuple_data] = table_info->table_->GetTupleWithLockAcquired(*rid, page);
*tuple = tuple_data;
++(*table_iterator_);
// MVCC 可见性判断(详见第 10 节)
auto tuple_ts = tuple_meta.ts_;
auto txn_ts = txn->GetReadTs();
if (tuple_ts > txn_ts && tuple_ts != txn->GetTransactionId()) {
// 需要沿 undo log 链回溯重建历史版本
// ...
}
// 谓词过滤
if (!is_deleted && 谓词满足) {
return true;
}
}
return false;
}
4.1.2 谓词下推(Predicate Pushdown)优化
SeqScan 的 PlanNode 持有 filter_predicate_,在扫描过程中就地过滤,避免产生无效 tuple 传递给上层 FilterExecutor:
// 在 SeqScan 内部过滤,减少传给上层算子的数据量
if (!is_deleted &&
!(plan_->filter_predicate_ != nullptr &&
!plan_->filter_predicate_->Evaluate(tuple, schema).GetAs<bool>())) {
return true;
}
优化器(Filter Predicate Pushdown 规则)会自动将 FilterPlanNode(SeqScanPlanNode) 合并为带谓词的 SeqScanPlanNode。
4.1.3 已知问题
// 问题:每次 Next() 调用时都重新查找 Catalog
auto table_info = exec_ctx_->GetCatalog()->GetTable(plan_->GetTableOid());
// 优化:应在 Init() 中缓存 table_info 指针
这个 unordered_map 查找虽然均摊 O(1),但对高频调用的热路径仍有不必要开销。
4.1.4 TableHeap 与 TableIterator
TableHeap 是 BusTub 的堆文件存储结构:
- 数据以 Page(4KB)为单位存储在 Buffer Pool 中
- 每个 Page 内部是
TablePage,使用 Slotted Page 格式 TableIterator按 page_id 顺序、按 slot 顺序扫描所有 tuple
TableHeap
├── Page 0 (TablePage)
│ ├── Header (free space pointer, slot count, ...)
│ ├── Slot 0 → Tuple data
│ ├── Slot 1 → Tuple data (deleted)
│ └── Slot 2 → Tuple data
├── Page 1 (TablePage)
│ └── ...
└── ...
4.2 InsertExecutor
文件: src/execution/insert_executor.cpp
4.2.1 执行模式 — 一次性算子
Insert/Update/Delete 算子都有一个关键设计:使用 has_inserted_ 标志位,确保整个批量操作在 Next() 的第一次调用中完整执行,输出一条"受影响行数"的 tuple,第二次调用直接返回 false:
auto InsertExecutor::Next([[maybe_unused]] Tuple *tuple, RID *rid) -> bool {
if (has_inserted_) { return false; } // 幂等保护
has_inserted_ = true;
int count = 0;
while (child_executor_->Next(tuple, rid)) {
InsertTuple(txn, txn_mgr, table_info, indexes, *tuple);
++count;
}
// 输出受影响行数
std::vector<Value> result{{TypeId::INTEGER, count}};
*tuple = Tuple{result, &GetOutputSchema()};
return true;
}
为什么要这样设计?
SQL 的 INSERT INTO ... SELECT ... 语义要求先完整读取所有源数据,再一次性写入。同时,上层调用者期望收到一条表示"受影响行数"的整数 tuple,这要求在所有行都插入完成后才能统计。
4.2.2 InsertTuple 逻辑(execution_common.cpp)
InsertTuple() 封装了完整的带 MVCC 的插入逻辑:
InsertTuple(txn, txn_mgr, table_info, indexes, tuple):
Step 1: 检查所有索引是否存在冲突
for each index:
ScanKey(tuple.key) → 若找到 RID:
若对应 tuple 未删除 → 唯一键冲突,abort 事务
若对应 tuple 已删除但被其他进行中的事务操作 → 写-写冲突,abort 事务
Step 2A: 若无冲突(全新插入):
TableHeap::InsertTuple() → 分配新 RID
UpdateVersionLink(new_rid, VersionUndoLink{}, nullptr) // 初始化版本链
AppendWriteSet(table_oid, new_rid) // 记录写集合(用于 abort 时回滚)
for each index: InsertEntry(key, new_rid) // 更新所有索引
Step 2B: 若找到已删除的同键 tuple(重复利用旧 RID):
创建 UndoLog 记录删除状态(用于事务回滚)
UpdateTupleInPlace() 写入新数据,同时更新 ts_ = txn->GetTransactionTempTs()
4.3 UpdateExecutor
文件: src/execution/update_executor.cpp
Update 是所有算子中 MVCC 逻辑最复杂的,需要仔细阅读。
4.3.1 两阶段执行
当前实现采用"先收集,再写入"的两阶段策略:
Phase 1(收集): 扫描所有待更新的 tuple,暂存到内存
while child_executor_->Next():
计算 new_values (by target_expressions_)
old_tuples.push_back(*tuple)
new_tuples.push_back(new_tuple)
rids.push_back(*rid)
Phase 2(写入): 判断是否涉及索引列,选择更新策略
if has_index_update:
for each rid: DeleteTuple() // 先全部删除
for each new_tuple: InsertTuple() // 再全部插入
else:
for each (rid, new_tuple): InPlaceUpdate() + 维护 UndoLog
为什么要两阶段?
- 避免 Halloween Problem:如果一边扫描一边更新,可能扫描到刚刚更新过的 tuple(被更新的 tuple 移动到了还未扫描的位置),导致一行被更新多次。两阶段将读写分离,彻底避免此问题。
- 索引更新的原子性:若索引列发生变化,需要先删除旧索引项再插入新索引项,批量操作更安全。
4.3.2 UndoLog 维护 — MVCC 精华
无索引更新路径中,需要为每条 tuple 维护 undo log(用于事务回滚和历史版本读取):
情况一:事务第一次写这条 tuple(tuple_meta.ts_ <= txn->GetReadTs()):
1. 对比 cur_tuple 与 new_tuple 的每列值
2. 生成 modified_fields[] 位图(哪些列变了)
3. 生成 modified_values[] 存储旧值
4. 创建 UndoLog{is_deleted=false, modified_fields, modified_tuple, ts=tuple_meta.ts_, prev=old_undo_link}
5. undo_link = txn->AppendUndoLog(undo_log) // 追加到事务 undo log 数组
6. txn_mgr->UpdateVersionLink(rid, {undo_link, true}) // 更新版本链头
7. txn->AppendWriteSet(table_oid, rid) // 加入写集
8. UpdateTupleInPlace(new_tuple) 写入最新数据
情况二:事务再次写同一条 tuple(tuple_meta.ts_ == txn->GetTransactionId()):
// 目标:合并 undo log,保证 undo 操作始终能还原到事务开始时的原始状态
1. 取出当前 undo_log(记录的是第一次修改相对于原始状态的差异)
2. 通过 ReconstructTuple() 重建原始 tuple(事务开始时的状态)
3. 对比 new_values 与 original_tuple 的差异,生成新的 modified_fields
4. txn->ModifyUndoLog(idx, new_undo_log) // 原地更新已有 undo log
为什么要合并而不是追加? 若事务多次修改同一行(如 UPDATE t SET a=2 WHERE id=1; UPDATE t SET a=3 WHERE id=1;),若每次都追加 undo log,则 undo 链条会不断增长,增加回滚时的开销。合并后,undo log 只记录"相对事务开始时刻的净变化",链条长度保持为 1。
4.3.3 索引更新路径
// 检查 target_expressions_ 中是否有非 ColumnValueExpression 的表达式(即有实际计算)
for (uint32_t col_idx = 0; col_idx < schema.GetColumnCount(); ++col_idx) {
auto *column_value_expr = dynamic_cast<const ColumnValueExpression *>(expr.get());
if (column_value_expr == nullptr) { // 该列有实际修改
for (auto index : indexes) {
if (该索引包含 col_idx) {
has_index_update = true;
}
}
}
}
当涉及索引列更新时,必须走 Delete+Insert 路径,而不能 in-place 更新,原因是:
- 索引存储的是旧的 key 值,in-place 更新 tuple 后,索引项仍指向旧 key,导致索引与数据不一致
- 必须先用旧 key 删除索引项,再用新 key 插入新索引项
4.4 DeleteExecutor
文件: src/execution/delete_executor.cpp
Delete 逻辑相对简单,委托给 DeleteTuple() 辅助函数:
auto DeleteExecutor::Next([[maybe_unused]] Tuple *tuple, RID *rid) -> bool {
if (has_deleted_) { return false; }
has_deleted_ = true;
int count = 0;
while (child_executor_->Next(tuple, rid)) {
DeleteTuple(txn, txn_mgr, table_info, *rid);
++count;
}
// 返回受影响行数
*tuple = Tuple{{TypeId::INTEGER, count}, &GetOutputSchema()};
return true;
}
DeleteTuple 的 MVCC 逻辑(execution_common.cpp:66):
DeleteTuple(txn, txn_mgr, table_info, rid):
加 TablePage 写锁
读取 tuple_meta 和当前 tuple 数据
Case 1: tuple_meta.ts_ <= txn->GetReadTs() (已提交事务的数据)
→ 创建 UndoLog{is_deleted=false, all_fields=true, 完整旧 tuple, ts=原始ts, prev=old_link}
→ UpdateVersionLink(VersionUndoLink{new_link, true})
→ AppendWriteSet(rid)
→ page->UpdateTupleMeta({txn_temp_ts, is_deleted=true}) // 标记删除
Case 2: tuple_meta.ts_ == txn->GetTransactionId() (本事务已修改过)
→ 若上次操作是非删除的修改:
取出已有 undo_log,重建原始 tuple
修改 undo_log 中的 modified_fields 为全 true,记录完整旧值
ModifyUndoLog() 原地更新
→ 将 tuple 标记 is_deleted=true(如果之前是 Insert,则直接变成"从未存在")
Case 3: tuple_meta.ts_ > txn->GetReadTs() (写-写冲突)
→ txn->SetTainted() + throw ExecutionException("write-write conflict")
4.5 IndexScanExecutor
文件: src/execution/index_scan_executor.cpp
通过哈希索引进行点查(Point Lookup),是 SeqScan 的优化替代方案(由优化器决策)。
4.5.1 执行流程
auto IndexScanExecutor::Next(Tuple *tuple, RID *rid) -> bool {
if (has_scanned_) { return false; } // 点查只执行一次
has_scanned_ = true;
// 从计划节点获取查询键值
auto value = plan_->pred_key_->val_;
std::vector<Value> values{value};
Tuple index_key(values, &key_schema);
// 哈希索引点查,获取 RID 列表
std::vector<RID> rids;
auto htable = dynamic_cast<HashTableIndexForTwoIntegerColumn *>(index_info->index_.get());
htable->ScanKey(index_key, &rids, exec_ctx_->GetTransaction());
if (rids.empty()) { return false; }
*rid = rids[0];
// 读取 tuple + MVCC 可见性判断(与 SeqScan 逻辑完全相同)
// ...
}
4.5.2 哈希索引的局限
BusTub 在 Project 2 实现的是可扩展哈希索引(Extendible Hash Table),因此 IndexScan 只支持等值查询,无法支持范围查询(col > 5、col BETWEEN 3 AND 7)。若需支持范围查询,需要 B+ 树索引(BusTub 另有实现,但 P3 不涉及)。
4.5.3 MVCC 在 IndexScan 中的处理
IndexScan 获取到 RID 后,同样需要走完整的 MVCC 可见性判断流程,与 SeqScan 的逻辑完全一致。这说明 MVCC 逻辑与数据访问方式无关,所有访问路径都需要经过可见性过滤。
5. Expression 表达式系统
表达式系统是执行引擎的基础设施,所有算子都依赖它来:
- 计算过滤谓词(Filter)
- 计算列值(Projection)
- 计算连接键(HashJoin)
- 计算聚合输入值(Aggregation)
5.1 表达式类层次
AbstractExpression(抽象基类)
│ virtual Value Evaluate(const Tuple *, const Schema &) const = 0
│ virtual Value EvaluateJoin(const Tuple *left, const Schema &, ...) const = 0
│
├── ColumnValueExpression // 取某列的值,如 #0.1(第 0 个 child 的第 1 列)
├── ConstantValueExpression // 常量,如 42, 'hello'
├── ComparisonExpression // 比较,如 a = 1, b > 2
├── ArithmeticExpression // 算术,如 a + b, a * 2
├── LogicExpression // 逻辑,如 a AND b, a OR b
└── AggregateValueExpression // 引用聚合结果
5.2 表达式的树形结构
以 WHERE id = 1 AND age > 18 为例:
LogicExpression(AND)
├── ComparisonExpression(=)
│ ├── ColumnValueExpression(col=0) // id 列
│ └── ConstantValueExpression(1)
└── ComparisonExpression(>)
├── ColumnValueExpression(col=2) // age 列
└── ConstantValueExpression(18)
求值时递归调用 Evaluate(tuple, schema),叶节点取值,父节点合并:
// 以 ComparisonExpression 为例
auto Value = ComparisonExpression::Evaluate(tuple, schema) {
auto left = GetChildAt(0)->Evaluate(tuple, schema);
auto right = GetChildAt(1)->Evaluate(tuple, schema);
return left.CompareEquals(right) == CmpBool::CmpTrue
? ValueFactory::GetBooleanValue(true)
: ValueFactory::GetBooleanValue(false);
}
5.3 NULL 值的三值逻辑
SQL 遵循三值逻辑(3VL):TRUE、FALSE、UNKNOWN(NULL)。BusTub 中 NULL 参与的比较返回 CmpBool::CmpNull,Filter 在判断谓词时必须显式处理:
// FilterExecutor 中
auto value = filter_expr->Evaluate(tuple, schema);
if (!value.IsNull() && value.GetAs<bool>()) { // NULL 不通过过滤
return true;
}
6. Aggregation Executor — 聚合算子
文件: src/execution/aggregation_executor.cpp
头文件: src/include/execution/executors/aggregation_executor.h
6.1 聚合函数类型
BusTub 支持以下聚合函数(AggregationType 枚举):
CountStarAggregate—COUNT(*),计数所有行(包含 NULL)CountAggregate—COUNT(col),计数非 NULL 值SumAggregate—SUM(col),对非 NULL 值求和MinAggregate—MIN(col),最小值(忽略 NULL)MaxAggregate—MAX(col),最大值(忽略 NULL)
6.2 SimpleAggregationHashTable
聚合算子的核心数据结构,内部是一个 unordered_map:
class SimpleAggregationHashTable {
std::unordered_map<AggregateKey, AggregateValue> ht_;
// AggregateKey = {group_by_values},如 (dept_id, location) 是 GROUP BY 的键
// AggregateValue = {aggregate_results},如 (count, sum, min, max) 是聚合结果
};
聚合键(AggregateKey)的哈希函数:
// 通过 std::hash<AggregateKey> 特化实现
// 对多列键做组合哈希(Hash Combine)
size_t curr_hash = 0;
for (const auto &val : key.group_bys_) {
curr_hash = HashUtil::CombineHashes(curr_hash, HashUtil::HashValue(&val));
}
6.3 CombineAggregateValues — 增量合并
void CombineAggregateValues(AggregateValue *result, const AggregateValue &input) {
for (uint32_t i = 0; i < agg_exprs_.size(); i++) {
switch (agg_types_[i]) {
case CountStarAggregate: // COUNT(*): +1,不管输入值
result->aggregates_[i] = result->aggregates_[i].Add(Value{INTEGER, 1});
break;
case CountAggregate: // COUNT(col): 非 NULL 才 +1
if (!input.aggregates_[i].IsNull()) {
result->aggregates_[i] = IsNull ? 1 : result + 1;
}
break;
case SumAggregate: // SUM: 非 NULL 才加
if (!input.aggregates_[i].IsNull()) {
result->aggregates_[i] = IsNull ? input : result + input;
}
break;
case MinAggregate: // MIN: 非 NULL 且更小才更新
if (!input.IsNull() && (result.IsNull() || result > input)) {
result->aggregates_[i] = input;
}
break;
case MaxAggregate: // MAX: 非 NULL 且更大才更新
// ... 类似 MIN,方向相反
break;
}
}
}
初始值规则(重要):
COUNT(*)初始值为 0(计数从零开始)COUNT(col),SUM,MIN,MAX初始值为 NULL(空集的聚合结果是 NULL)
6.4 Pipeline Breaker 与两阶段执行
void AggregationExecutor::Init() {
child_executor_->Init();
aht_ = std::make_unique<SimpleAggregationHashTable>(...);
// ★ Pipeline Breaker:在 Init() 中消费所有子算子数据
Tuple tuple{}; RID rid{};
while (child_executor_->Next(&tuple, &rid)) {
aht_->InsertCombine(MakeAggregateKey(&tuple), MakeAggregateValue(&tuple));
}
aht_iterator_ = std::make_unique<Iterator>(aht_->Begin());
}
auto AggregationExecutor::Next(Tuple *tuple, RID *rid) -> bool {
// Init() 已完成全部聚合,Next() 只需遍历哈希表
if (*aht_iterator_ != aht_->End()) {
// 拼接 group_by_keys + aggregate_values 输出
++(*aht_iterator_);
return true;
}
// 空表特殊处理
if (!has_executed_ && plan_->group_bys_.empty()) {
has_executed_ = true;
// SELECT COUNT(*) FROM empty_table → 返回 (0),而非空结果
return true;
}
return false;
}
空表的边界情况(面试常考):
| 查询 | 有无 GROUP BY | 输入为空时的输出 |
|---|---|---|
SELECT COUNT(*) FROM t | 无 | 一行:(0) |
SELECT SUM(col) FROM t | 无 | 一行:(NULL) |
SELECT COUNT(*) FROM t GROUP BY dept | 有 | 空(无行) |
这是因为 SQL 标准规定:无 GROUP BY 时,即使输入为空,也要输出一行聚合结果;有 GROUP BY 时,无输入则无输出。
7. Join Executors — 连接算子
7.1 NestedLoopJoinExecutor
算法: 经典嵌套循环连接(O(n×m) 复杂度)
对外表(左表)的每一行 r:
对内表(右表)的每一行 s:
if JoinCondition(r, s):
输出 (r, s)
BusTub 实现: 内表每次都需要从头重新扫描(right_child_->Init()),这是最朴素的 NLJ 实现。优化版本(Block NLJ)会将外表数据缓存到 Buffer Pool 块中,减少内表扫描次数。
LEFT JOIN 处理: 对外表的每一行,若没有匹配的内表行,输出(外表行,NULL…)。
7.2 HashJoinExecutor
文件: src/execution/hash_join_executor.cpp
头文件: src/include/execution/executors/hash_join_executor.h
7.2.1 核心数据结构
// 连接键:多列值组成的复合键
struct HashJoinKey {
std::vector<Value> values_;
auto operator==(const HashJoinKey &other) const -> bool { /* 逐列比较 */ }
};
// 自定义哈希函数(注册到 std::hash)
namespace std {
template <>
struct hash<bustub::HashJoinKey> {
auto operator()(const HashJoinKey &key) const -> std::size_t {
size_t curr_hash = 0;
for (const auto &val : key.values_) {
if (!val.IsNull()) {
curr_hash = HashUtil::CombineHashes(curr_hash, HashUtil::HashValue(&val));
}
}
return curr_hash;
}
};
}
// 哈希表:key → 右表中匹配的所有行(支持一对多)
std::unordered_map<HashJoinKey, std::vector<HashJoinValue>> hash_table_;
7.2.2 Build + Probe 执行流程
// Build 阶段(在 Init() 中完成)
void HashJoinExecutor::Init() {
right_child_->Init();
while (right_child_->Next(&tuple, &rid)) {
auto key = MakeHashJoinKey(&tuple, right_expressions, right_schema);
hash_table_[key].push_back(MakeHashJoinValue(&tuple, right_schema));
}
}
// Probe 阶段(在 Next() 中流式进行)
auto HashJoinExecutor::Next(Tuple *tuple, RID *rid) -> bool {
// 先消耗已有缓存结果
if (!results_.empty()) {
*tuple = results_.front();
results_.pop_front();
return true;
}
// 继续探测左表
while (left_child_->Next(tuple, rid)) {
auto key = MakeHashJoinKey(tuple, left_expressions, left_schema);
if (hash_table_.find(key) != hash_table_.end()) {
// 找到匹配:右表可能有多行匹配,全部放入 results_ 缓冲
for (auto &right_val : hash_table_[key]) {
results_.push_back(合并左右tuple);
}
} else if (plan_->GetJoinType() == JoinType::LEFT) {
// LEFT JOIN:右侧填 NULL
results_.push_back(左表行 + NULL...);
}
if (!results_.empty()) {
*tuple = results_.front();
results_.pop_front();
return true;
}
}
return false; // 左表耗尽
}
7.2.3 HashJoin 的优势
与 NestedLoopJoin 相比:
- 时间复杂度: O(n + m) vs O(n × m)
- Build 阶段: O(m),扫描右表一次建哈希表
- Probe 阶段: O(n),扫描左表一次,每行 O(1) 查哈希表
哈希冲突处理: 使用 unordered_map + 链式法(std::list 内置),不同 key 的哈希碰撞由 STL 自动处理;相同 key 的多行匹配由 vector<HashJoinValue> 存储。
7.2.4 results_ 缓冲的设计意义
当一条左表行匹配多条右表行时(如 1 对 N 关系),Next() 一次只能返回一条 tuple。results_ deque 缓冲解决了"一次 probe 产生多个输出"的问题:
Left tuple A 匹配 Right 中的 [B1, B2, B3]
results_ = [(A,B1), (A,B2), (A,B3)]
Next() call 1: 返回 (A,B1),results_ = [(A,B2), (A,B3)]
Next() call 2: 返回 (A,B2),results_ = [(A,B3)]
Next() call 3: 返回 (A,B3),results_ = []
Next() call 4: 继续读左表...
7.2.5 已知问题与改进
右表全量 in-memory:Build 阶段将整个右表读入内存,若右表很大会 OOM。生产级系统采用 Grace Hash Join:
- 对两表按 join key 哈希分桶(partition),写入磁盘
- 每对分桶单独进行 in-memory hash join
- 理论上支持任意大小的输入
Build/Probe side 固定:当前实现固定右表为 build side,没有根据统计信息(行数、数据大小)自动选择。应将小表作为 build side,大表作为 probe side。
results_使用list(实为std::list<Tuple>):pop_front()是 O(1) 但有动态内存分配开销,改用 index 标记位置效率更高:
// 优化前
std::list<Tuple> results_; // pop_front() 有内存分配
// 优化后
std::vector<Tuple> results_;
size_t result_idx_ = 0; // 直接移动索引,避免内存分配
8. 高级算子
8.1 SortExecutor
文件: src/execution/sort_executor.cpp
8.1.1 全内存排序实现
void SortExecutor::Init() {
child_executor_->Init();
tuples_.clear();
// ★ Pipeline Breaker:必须消费所有 tuple 才能开始排序
Tuple tuple; RID rid;
while (child_executor_->Next(&tuple, &rid)) {
tuples_.emplace_back(tuple);
}
// 多列排序(ORDER BY col1 ASC, col2 DESC, ...)
std::sort(tuples_.begin(), tuples_.end(),
[this](const Tuple &lhs, const Tuple &rhs) {
for (const auto &order_by : plan_->GetOrderBy()) {
auto order_by_type = order_by.first;
auto expr = order_by.second.get();
auto lhs_val = expr->Evaluate(&lhs, plan_->OutputSchema());
auto rhs_val = expr->Evaluate(&rhs, plan_->OutputSchema());
if (lhs_val.CompareLessThan(rhs_val) == CmpBool::CmpTrue) {
return order_by_type != OrderByType::DESC; // ASC: lhs < rhs → true
}
if (lhs_val.CompareGreaterThan(rhs_val) == CmpBool::CmpTrue) {
return order_by_type == OrderByType::DESC; // DESC: lhs > rhs → true
}
// 相等则继续比较下一列
}
return true;
});
curr_pos_ = 0;
}
8.1.2 外部排序(External Sort-Merge)
生产级系统对无法全量放入内存的数据需要外部排序:
Phase 1 (Run Generation):
将数据按 Buffer Pool 大小分块读入
在内存中排序每块 → 生成有序的 Run 文件写入磁盘
Phase 2 (Merge):
使用 K 路归并(K-way Merge)合并所有 Run 文件
每次从每个 Run 的头部取最小值(最大堆辅助)
→ 输出全局有序数据
BusTub 当前实现不支持外部排序,这是生产环境中的重要限制。
8.1.3 排序稳定性
std::sort 是不稳定排序(QuickSort/IntroSort),对于相等的元素不保证原始相对顺序。若需要稳定排序(如 ORDER BY col LIMIT N 后的确定性),应使用 std::stable_sort(基于 MergeSort)。
当前 comparator 的 return true fallback(两 tuple 完全相等时)可能导致 UB(严格弱序要求 comp(x,x) 返回 false),更严格的实现应返回 false。
8.2 LimitExecutor
文件: src/execution/limit_executor.cpp
Limit 是少数几个**流式(Streaming)**执行的算子(非 Pipeline Breaker):
auto LimitExecutor::Next(Tuple *tuple, RID *rid) -> bool {
if (count_ >= limit_) { return false; } // 达到上限,终止
if (child_executor_->Next(tuple, rid)) {
count_++;
return true;
}
return false;
}
提前终止的威力: 对于 SELECT * FROM large_table LIMIT 10,Limit 算子只拉取 10 条后即停止,子算子(如 SeqScan)不会继续扫描剩余数据,这是火山模型的核心优势之一。
与 TopN 的区别: Limit 不做排序,直接截取前 N 条;TopN 配合 Sort 使用,取排序后的前 N 条(但 BusTub 优化器会将 Sort+Limit 替换为单个 TopN)。
8.3 TopNExecutor — 堆优化
文件: src/execution/topn_executor.cpp
头文件: src/include/execution/executors/topn_executor.h
8.3.1 优化动机
朴素的 ORDER BY col LIMIT N 需要:
- 读取所有数据(O(n))
- 全量排序(O(n log n))
- 截取前 N 条
优化后的 TopN 算法(堆维护):
- 读取所有数据,维护大小为 N 的堆(O(n log N))
- 直接输出堆中的 N 条数据
当 N « n 时,O(n log N) 显著优于 O(n log n)。
8.3.2 比较器设计
struct Compare {
explicit Compare(const TopNPlanNode *plan) : plan_(plan) {}
// 返回 true 意味着 lhs "更差"(应该被堆 pop 掉)
// 对于 ASC 排序取前 N 小:使用最大堆,"更差" = 更大
auto operator()(const Tuple &lhs, const Tuple &rhs) const -> bool {
for (const auto &order_by : plan_->GetOrderBy()) {
auto order_by_type = order_by.first;
auto lhs_val = expr->Evaluate(&lhs, ...);
auto rhs_val = expr->Evaluate(&rhs, ...);
if (lhs_val.CompareLessThan(rhs_val) == CmpBool::CmpTrue) {
return order_by_type != OrderByType::DESC;
// ASC: lhs < rhs, lhs 更好,返回 false(lhs 不应被 pop)
// 但 priority_queue 是 max-heap,比较器返回 true 意味着 lhs 优先级更低
}
// ...
}
return true;
}
};
堆的选择: std::priority_queue 是最大堆(最大元素在堆顶)。对于 ORDER BY col ASC LIMIT N(取最小的 N 个),我们希望堆里保留最小的 N 个,所以要把最大的 pop 出去。当堆顶(最大元素)比新来的元素大时,pop 堆顶,push 新元素。
8.3.3 实现细节
void TopNExecutor::Init() {
// 使用反序比较器的最大堆
auto top_entries = std::priority_queue<Tuple, std::vector<Tuple>, Compare>(Compare(plan_));
while (child_executor_->Next(&tuple, &rid)) {
top_entries.push(tuple);
if (top_entries.size() > plan_->GetN()) {
top_entries.pop(); // 弹出最差的(最大的),保留最优的 N 个
}
}
// 堆中的元素是逆序的(最差的先出来),需要翻转
while (!top_entries.empty()) {
top_tuples_.emplace_back(top_entries.top());
top_entries.pop();
}
std::reverse(top_tuples_.begin(), top_tuples_.end()); // 还原为正确顺序
curr_pos_ = 0;
}
8.4 WindowFunctionExecutor
文件: src/execution/window_function_executor.cpp
头文件: src/include/execution/executors/window_function_executor.h
8.4.1 窗口函数概念
窗口函数(Window Function)与普通聚合函数的本质区别:
| 特性 | 普通聚合(GROUP BY) | 窗口函数(OVER) |
|---|---|---|
| 输出行数 | 每组一行(行数减少) | 与输入相同(行数不变) |
| 数据访问 | 组内所有行 | 每行的"窗口"内的行 |
| 组合普通列 | 只能输出 GROUP BY 列 | 可以同时输出普通列 |
典型示例:
-- 普通聚合:3 个部门 → 3 行结果
SELECT dept_id, SUM(salary) FROM employees GROUP BY dept_id;
-- 窗口函数:每行都保留,额外计算部门内累计薪资
SELECT emp_id, dept_id, salary,
SUM(salary) OVER (PARTITION BY dept_id ORDER BY hire_date) AS running_total
FROM employees;
-- 输出与输入等行数,但每行多了 running_total 列
8.4.2 PlanNode 结构
WindowFunctionPlanNode 的结构(来自 aggregation_plan.h):
columns_: [col0, col1, placeholder(-1), placeholder(-1)]
↑ ↑ ↑ ↑
普通列 普通列 窗口函数列1 窗口函数列2
window_functions_: {
2: WindowFunction{
function_: SUM(salary)
type_: SumAggregate
partition_by_: [dept_id]
order_by_: [(ASC, hire_date)]
},
3: WindowFunction{
function_: RANK()
type_: Rank
partition_by_: [dept_id]
order_by_: [(DESC, salary)]
}
}
col_idx == -1(实现中用 static_cast<uint32_t>(-1) = 最大 uint32)作为"占位符"标记,区分普通列和窗口函数列。
8.4.3 SimpleWindowFunctionHashTable
为每个窗口函数维护一个独立的哈希聚合表:
Key = PARTITION BY 列的值组合(分区键)
Value = 该分区内的累积聚合值
例:PARTITION BY dept_id, ORDER BY hire_date 时:
key=(10) → value=running_sum_for_dept_10
key=(20) → value=running_sum_for_dept_20
8.4.4 执行流程
void WindowFunctionExecutor::Init() {
// Step 1: 读取所有 child tuples
while (child_executor_->Next(&tuple, &rid)) {
tuples.emplace_back(tuple);
}
// Step 2: 若有 ORDER BY,对所有 tuples 排序(所有窗口函数共享同一排序)
if (有 order_by) {
std::sort(tuples.begin(), tuples.end(), 按 order_by 排序);
}
// Step 3: 为每个窗口函数创建 HashTable
for (each window_function):
SimpleWindowFunctionHashTable aht = ...;
if (!has_order_by):
for (each tuple): aht.InsertCombine(tuple); // 预聚合
ahts.push_back(aht);
// Step 4: 遍历每条 tuple,组装最终输出
for (each tuple):
values = []
for (each output_col):
if (是普通列): values.push(tuple.GetValue(col_idx))
else: // 窗口函数列
if (has_order_by):
values.push(aht.InsertCombine(tuple)) // 流式累积
else:
values.push(aht.Find(tuple)) // 查预计算结果
results_.push_back(Tuple(values, output_schema))
}
8.4.5 RANK() 的特殊实现
RANK() 不是普通聚合函数,它的语义是"当前行在当前分区内的排名(相同值同名次,跳过)":
// SimpleWindowFunctionHashTable::CombineWindowAggregateValues
case WindowFunctionType::Rank:
++rank_count_; // 全局计数器,统计已处理多少行
if (result->GetAs<int32_t>() != input.GetAs<int32_t>()) {
// 值变了(不同排名),更新 last_rank_count_ 为当前行号
*result = input;
last_rank_count_ = rank_count_;
}
// 返回 last_rank_count_(相同值的行返回相同排名)
return ValueFactory::GetIntegerValue(last_rank_count_);
注意:RANK() 的 build side 哈希表的 key 使用 ORDER BY 表达式的值,而其他聚合函数使用 PARTITION BY 的值。这是一个设计上的特殊处理,在 Window Executor 构造时区分:
SimpleWindowFunctionHashTable aht =
(window_function_type == WindowFunctionType::Rank)
? SimpleWindowFunctionHashTable{order_by[0].second, win_type, partition_by, schema}
: SimpleWindowFunctionHashTable{function, win_type, partition_by, schema};
8.4.6 已知限制
- 不支持 Window Frame:如
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW(滑动窗口) - 当前实现的语义等价于:
- 有 ORDER BY 时:
UNBOUNDED PRECEDING AND CURRENT ROW(前缀聚合) - 无 ORDER BY 时:
UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING(全区间聚合)
- 有 ORDER BY 时:
- RANK 的
rank_count_是成员变量,在同一执行中不可重复使用(不能 re-init)
9. 辅助算子
9.1 ProjectionExecutor
文件: src/execution/projection_executor.cpp
最简单的算子,对子算子的每条 tuple 进行列变换:
auto ProjectionExecutor::Next(Tuple *tuple, RID *rid) -> bool {
Tuple child_tuple{};
if (!child_executor_->Next(&child_tuple, rid)) { return false; }
std::vector<Value> values{};
values.reserve(GetOutputSchema().GetColumnCount());
for (const auto &expr : plan_->GetExpressions()) {
// 每个表达式对子 tuple 求值,可以是列引用、运算、常量等
values.push_back(expr->Evaluate(&child_tuple, child_executor_->GetOutputSchema()));
}
*tuple = Tuple{values, &GetOutputSchema()};
return true;
}
Projection 实现了 SQL 的 SELECT 子句(列选择和计算),例如:
SELECT id, salary * 1.1 AS new_salary FROM employees;
-- GetExpressions() = [ColumnValueExpr(col=0), ArithmeticExpr(ColumnValueExpr(col=2), *, Constant(1.1))]
9.2 FilterExecutor
文件: src/execution/filter_executor.cpp
实现 SQL 的 WHERE 子句过滤:
auto FilterExecutor::Next(Tuple *tuple, RID *rid) -> bool {
auto filter_expr = plan_->GetPredicate();
while (true) {
if (!child_executor_->Next(tuple, rid)) { return false; }
auto value = filter_expr->Evaluate(tuple, child_executor_->GetOutputSchema());
if (!value.IsNull() && value.GetAs<bool>()) {
return true; // 满足谓词,向上返回
}
// 不满足,继续拉取子算子
}
}
与 SeqScan 内置谓词的关系:
优化器的 Predicate Pushdown 规则会尝试将 FilterExecutor 的谓词下推到 SeqScan 的 filter_predicate_,从而消除单独的 FilterExecutor 节点,减少 tuple 在算子间的传递开销。
9.3 ValuesExecutor
文件: src/execution/values_executor.cpp
用于 INSERT INTO t VALUES (...) 中的常量值,或 SELECT 1, 'hello' 这类不需要扫描表的查询:
auto ValuesExecutor::Next(Tuple *tuple, RID *rid) -> bool {
if (cursor_ >= plan_->GetValues().size()) { return false; }
const auto &row_expr = plan_->GetValues()[cursor_];
std::vector<Value> values{};
for (const auto &col : row_expr) {
// dummy_schema_ 是空 Schema(VALUES 的列不来自任何表)
values.push_back(col->Evaluate(nullptr, dummy_schema_));
}
*tuple = Tuple{values, &GetOutputSchema()};
cursor_ += 1;
return true;
}
10. MVCC 多版本并发控制
MVCC(Multi-Version Concurrency Control)允许读操作不阻塞写操作,通过为每个数据行维护多个历史版本来实现快照隔离(Snapshot Isolation)。
10.1 版本链数据结构
TableHeap 中的最新版本
TupleMeta.ts_ = 提交事务的 commit_ts,或未提交事务的 TXN_TEMP_TS
TupleMeta.is_deleted_ = bool(是否为删除标记)
↓ TransactionManager::GetVersionLink(rid)
VersionUndoLink(版本链头)
prev_ = UndoLink(指向第一个 UndoLog)
in_progress_ = bool(是否有事务正在修改)
↓ UndoLink.prev_log_idx_ / txn_id
UndoLog 1(最近一次修改的逆操作)
is_deleted_: bool // 修改前是否已删除
modified_fields_: vector<bool> // 哪些列被修改了
tuple_: Tuple // 修改前的值(只含 modified 的列)
ts_: timestamp_t // 修改前的时间戳
prev_version_: UndoLink // 指向更早的 UndoLog
↓ prev_version_
UndoLog 2 → UndoLog 3 → ... → nullptr
时间戳规则:
- 已提交事务:
ts_ = commit_ts(单调递增的逻辑时钟) - 进行中事务:
ts_ = TXN_TEMP_TS = txn->GetTransactionTempTs()(基于 txn_id,格式为 TXN_START_ID + txn_id) - 判断 tuple 是否正在被未提交事务修改:
ts_ >= TXN_START_ID
10.2 可见性判断逻辑
对于事务 T(read_ts = T.GetReadTs())读取 tuple 时:
if tuple_ts == T.GetTransactionId():
→ 这是 T 自己修改的,对 T 可见(读己之所写)
elif tuple_ts <= read_ts:
→ 已提交且在 T 开始前提交,对 T 可见
else (tuple_ts > read_ts):
→ 在 T 开始后修改(未提交或其他事务提交)
→ 需要回溯 undo log,找到 ts_ <= read_ts 的版本
回溯逻辑(在 SeqScan / IndexScan 中实现):
if (tuple_ts > txn_ts && tuple_ts != txn->GetTransactionId()) {
std::vector<UndoLog> undo_logs;
UndoLink undo_link = txn_manager->GetUndoLink(*rid).value_or(UndoLink{});
while (optional_undo_log.has_value() && tuple_ts > txn_ts) {
undo_logs.push_back(*optional_undo_log);
tuple_ts = optional_undo_log->ts_; // 更新为该 undo log 之前的时间戳
undo_link = optional_undo_log->prev_version_;
optional_undo_log = txn_manager->GetUndoLogOptional(undo_link);
}
if (tuple_ts > txn_ts) { continue; } // 版本链全都太新,不可见
auto new_tuple = ReconstructTuple(&schema, *tuple, tuple_meta, undo_logs);
if (!new_tuple.has_value()) { continue; } // 历史版本是已删除状态
}
10.3 ReconstructTuple
文件: src/execution/execution_common.cpp:17
给定 base_tuple(最新版本)和按从新到旧排列的 undo_logs,逐步回滚恢复历史版本:
auto ReconstructTuple(const Schema *schema, const Tuple &base_tuple,
const TupleMeta &base_meta,
const std::vector<UndoLog> &undo_logs) -> std::optional<Tuple> {
bool is_deleted = base_meta.is_deleted_;
std::vector<Value> values;
// 初始化为最新版本的所有列值
for (uint32_t i = 0; i < schema->GetColumnCount(); ++i) {
values.push_back(base_tuple.GetValue(schema, i));
}
for (const auto &undo_log : undo_logs) {
if (undo_log.is_deleted_) {
// 这个 undo log 表示在它之前的版本是"已删除"状态
is_deleted = true;
for (auto &val : values) val = NULL;
} else {
is_deleted = false;
// 按 modified_fields_ 位图还原被修改的列
std::vector<uint32_t> cols;
for (uint32_t i = 0; i < undo_log.modified_fields_.size(); ++i) {
if (undo_log.modified_fields_[i]) cols.push_back(i);
}
Schema undo_schema = Schema::CopySchema(schema, cols);
for (uint32_t i = 0, j = 0; i < modified_fields.size(); ++i) {
if (modified_fields[i]) {
values[i] = undo_log.tuple_.GetValue(&undo_schema, j++);
}
}
}
}
if (is_deleted) return std::nullopt;
Tuple res = Tuple(values, schema);
res.SetRid(base_tuple.GetRid());
return res;
}
UndoLog 的稀疏存储优化: modified_fields_ 是一个 vector<bool> 位图,tuple_ 中只存储发生变化的列值,而非整行。这样对于只修改少数列的 UPDATE,undo log 存储开销远小于整行存储。
例如,一个 100 列的表,只更新第 3 列,undo log 的 tuple_ 中只有第 3 列的旧值,而不是 100 列的完整数据。
10.4 写-写冲突检测
在所有写操作前:
// 若 tuple_ts > txn->GetReadTs() 且不是本事务修改的
// 说明在 T 的 snapshot 之后,有另一个事务(已提交或未提交)修改了这条 tuple
if (tuple_meta.ts_ > txn->GetReadTs() && tuple_meta.ts_ != txn->GetTransactionId()) {
txn->SetTainted();
throw ExecutionException("write-write conflict");
}
这实现的是First-Writer-Wins规则:第一个修改某行的事务获胜,后来的事务需要 abort 并重试。
11. 查询优化器规则
BusTub 的优化器采用规则优化(Rule-Based Optimization, RBO),按固定顺序应用优化规则对计划树进行变换。
11.1 优化器的整体结构
优化器的入口在 src/optimizer/optimizer.cpp,规则按顺序应用:
1. Filter Predicate Pushdown → 将 Filter 下推至 SeqScan
2. Column Pruning → 删除不必要的列(可选)
3. OptimizeSeqScanAsIndexScan → SeqScan+等值谓词 → IndexScan
4. OptimizeNLJAsHashJoin → NestedLoopJoin+等值条件 → HashJoin
5. OptimizeSortLimitAsTopN → Sort+Limit → TopN
6. ...
每条规则实现为 Optimizer::OptimizeXxx(const AbstractPlanNodeRef &plan) 方法,递归遍历计划树并替换匹配的子树。
11.2 SeqScan → IndexScan 优化
文件: src/optimizer/seqscan_as_indexscan.cpp
规则描述: 当 SeqScan 的谓词满足特定形式(单列等值)且该列上有索引时,替换为 IndexScan。
auto Optimizer::OptimizeSeqScanAsIndexScan(const AbstractPlanNodeRef &plan)
-> AbstractPlanNodeRef {
// 递归优化子节点
std::vector<AbstractPlanNodeRef> children;
for (const auto &child : plan->GetChildren()) {
children.emplace_back(OptimizeSeqScanAsIndexScan(child));
}
auto optimized_plan = plan->CloneWithChildren(children);
// 匹配:SeqScan + 谓词为等值比较(col = const)
if (optimized_plan->GetType() == PlanType::SeqScan) {
const auto &seq_scan_plan = dynamic_cast<SeqScanPlanNode &>(*optimized_plan);
auto predicate = seq_scan_plan.filter_predicate_;
if (predicate != nullptr) {
auto comparison_expr = std::dynamic_pointer_cast<ComparisonExpression>(predicate);
if (comparison_expr != nullptr && comparison_expr->comp_type_ == ComparisonType::Equal) {
auto column_expr = std::dynamic_pointer_cast<ColumnValueExpression>(comparison_expr->GetChildAt(0));
auto constant_expr = std::dynamic_pointer_cast<ConstantValueExpression>(comparison_expr->GetChildAt(1));
if (column_expr != nullptr && constant_expr != nullptr) {
auto column_idx = column_expr->GetColIdx();
// 查找该列上的索引
for (auto &index_info : catalog_.GetTableIndexes(table_name)) {
auto attrs = index_info->index_->GetKeyAttrs();
if (std::find(attrs.begin(), attrs.end(), column_idx) != attrs.end()) {
// 创建 IndexScanPlanNode 替换 SeqScanPlanNode
return std::make_shared<IndexScanPlanNode>(
output_schema, table_oid, index_oid, predicate, constant_expr.get());
}
}
}
}
}
}
return optimized_plan;
}
规则的局限性:
- 只支持等值谓词(
ComparisonType::Equal):WHERE id = 5可以,WHERE id > 5不行 - 只支持左列右常量(
col = const):1 = id这种反向写法不匹配 - 只支持单列等值:
WHERE id = 5 AND name = 'Alice'的复合条件不支持 - 无代价估算:不检查索引的选择率,若列基数很低(大量重复值),走索引反而比 SeqScan 更慢(随机 I/O 开销 > 顺序 I/O 开销)
- 只支持当前哈希索引:若有 B+ 树索引,可以支持范围谓词
11.3 NestedLoopJoin → HashJoin 优化
规则描述: 当 NLJ 的连接条件是多个等值条件的合取(AND)时,替换为 HashJoin。
NLJ(condition: a1=b1 AND a2=b2)
→ HashJoin(left_keys=[a1, a2], right_keys=[b1, b2])
等值连接是数据库中最常见的 Join 类型,HashJoin 的 O(n+m) 相比 NLJ 的 O(n×m) 有数量级的优势。
11.4 Sort + Limit → TopN 优化
规则描述: 识别 LimitPlanNode(SortPlanNode(...)) 的计划模式,替换为单个 TopNPlanNode。
Limit(n=10)
└─ Sort(ORDER BY salary DESC)
→ TopN(n=10, ORDER BY salary DESC)
优化效果: 时间复杂度从 O(n log n)(全排序)+ O(1)(取前 10)降至 O(n log 10)(维护大小 10 的堆)。
思考
Project3 的难点还是在于读代码,了解整个项目的设计结构,具体实现也就是一些常用的执行器的实现以及实现了几个优化器,但是也并不难。整体来说还是收获到很多东西,这一部分可能写的不是很详细,一是时间已经过去很久了,记不太清了,二是在后续 Project4 中会修改很多地方,导致代码已经变化很多了。
本文在当时的实现总结基础上,对 Project3 中的核心机制(火山模型、各类执行器、MVCC、优化器规则)进行了系统整理,补充了大量设计原理分析和面试常考知识点,希望对后来者有所帮助。
附录:代码关键文件索引
| 文件 | 内容 |
|---|---|
src/execution/seq_scan_executor.cpp | 顺序扫描,MVCC 可见性判断 |
src/execution/insert_executor.cpp | 插入算子,一次性执行模式 |
src/execution/update_executor.cpp | 更新算子,两阶段 + UndoLog 合并 |
src/execution/delete_executor.cpp | 删除算子,DeleteTuple 封装 |
src/execution/index_scan_executor.cpp | 索引点查 |
src/execution/aggregation_executor.cpp | 哈希聚合,空表边界处理 |
src/execution/hash_join_executor.cpp | Build+Probe 哈希连接 |
src/execution/sort_executor.cpp | 全内存排序 |
src/execution/limit_executor.cpp | 流式截断 |
src/execution/topn_executor.cpp | 堆维护 TopN |
src/execution/window_function_executor.cpp | 窗口函数 |
src/execution/execution_common.cpp | MVCC 公共函数(ReconstructTuple, InsertTuple, DeleteTuple) |
src/optimizer/seqscan_as_indexscan.cpp | SeqScan→IndexScan 优化规则 |
src/include/execution/executors/abstract_executor.h | Executor 基类接口 |
src/include/execution/executors/aggregation_executor.h | SimpleAggregationHashTable |
src/include/execution/executors/hash_join_executor.h | HashJoinKey/Value 与哈希函数 |
src/include/execution/executors/topn_executor.h | TopN Compare 函子 |
src/include/execution/executors/window_function_executor.h | SimpleWindowFunctionHashTable |
src/include/execution/plans/abstract_plan.h | PlanNode 基类,PlanType 枚举 |