项目经历
从去年十月初到今年一月中旬,历时一个学期,在实验室的安排下,着手开始 CMU 15445 23fall 的数据库知识的学习和 Project 的实现,终于是在过年前完成所有的 Project。正好寒假在家有时间,就着手建了一个个人博客,写一下我在实现 Project 过程中遇到的问题和收获。关于课程视频,我时间有限,且没有太大兴趣,就只看了前几个视频就没看了,如果有同学感兴趣的话,还是推荐看一下,理论知识的学习还是很重要滴。
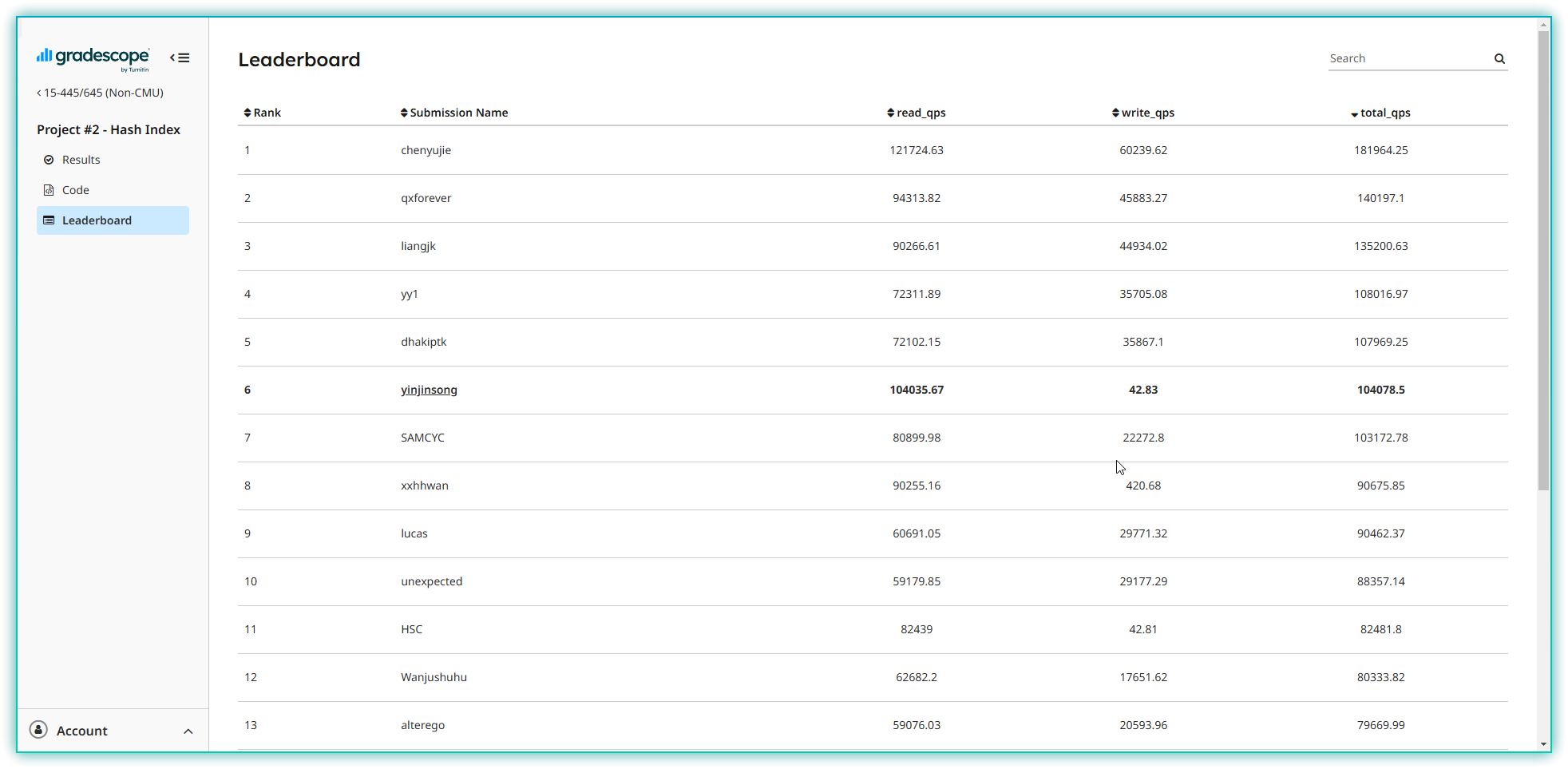
Project2 开始涉及到数据库索引的底层实现,当年(23fall)做的是可扩展哈希,相比于 B+ 树要简单不少,推荐学有余力的同学去做一下其他年份的 B+ 树。总体来说没做多久,比 Project1 花的时间稍多一点。LeaderBoard 结果截止 2025/01/30 排名第 6:
时隔一年后重新整理这篇文章,结合当时的实现思路和现在更系统的理解,做一次完整的复习总结。
1. 概述
本项目是 CMU 15-445/645 数据库系统课程(Fall 2023)的 Project 2,要求实现一个磁盘支持的可扩展哈希索引(Disk-Backed Extendible Hash Index),具备以下能力:
- 支持唯一键的查找(GetValue)、插入(Insert)、删除(Remove)
- 支持桶的动态分裂(Split)与合并(Merge),以及目录的扩展与收缩
- 通过 BufferPoolManager 管理磁盘页面
- 线程安全,支持多线程并发操作(Latch Crabbing)
项目分为四个任务:
- Task 1:实现
BasicPageGuard、ReadPageGuard、WritePageGuard(RAII 式页面锁管理) - Task 2:实现三种页面类——Header Page、Directory Page、Bucket Page
- Task 3:实现可扩展哈希的核心逻辑(Insert / GetValue / Remove)
- Task 4:实现并发控制(Latch Crabbing 算法)
2. 整体架构
2.1 三层存储结构
┌─────────────────────┐
│ Header Page │ 固定 1 页,存储 Directory Page IDs
│ directory_page_ids_ │ 用哈希值的高位(MSB)做索引
└─────────┬───────────┘
│ 1..N 个 Directory Pages
┌───────────────────┼───────────────────────┐
│ │ │
┌───────┴───────┐ ┌───────┴───────┐ ┌───────┴───────┐
│ Directory Page│ │ Directory Page│ ... │ Directory Page│
│ global_depth │ │ global_depth │ │ global_depth │
│ local_depths │ │ local_depths │ │ local_depths │
│ bucket_page_ids│ │ bucket_page_ids│ │ bucket_page_ids│
└───────┬───────┘ └───────┬───────┘ └───────┬───────┘
│ 1..2^GD 个 Bucket Pages(部分共享)
┌─────┴─────┐
│Bucket Page│ 存储实际 KV 对 array_[]
└───────────┘
2.2 哈希路由策略
| 层次 | 使用哈希位 | 方法 |
|---|---|---|
| Header → Directory | 最高 header_max_depth 位(MSB) | hash >> (32 - max_depth_) |
| Directory → Bucket | 最低 global_depth 位(LSB) | hash & ((1 << global_depth_) - 1) |
MSB 用于 Header、LSB 用于 Directory 的设计动机: Header 是全局唯一的热点页面,用 MSB 可以将不同前缀的 key 分散到不同 directory,减少对 Header 的竞争;Directory 内部用 LSB,与传统可扩展哈希一致,便于通过位翻转计算 split image。
3. 页面设计详解
当时的实现体会(Task 2): 这部分实现三层结构中各个 Page 的功能函数,包括初始化、插入、查找、删除等接口,基本按照函数名就能知道应该干什么,相应实现即可,整体比较简单。做的过程中顺便对三层结构有了更清晰的理解:bucket 层是实际存放 KV 的容器,所有的增删改查最终都落在这里,并且每个 key 在整个索引中是唯一的,插入前需要做重复性检查;directory 层是可扩展哈希的核心,负责向下管理桶的分裂与合并(也是整个项目最难的部分),同时向上提供索引指向;header 层则类似操作系统多级页表中的外层页表,用于将请求分发到不同的 directory,同时提升了并发度——不同 header 槽下的 directory 之间天然可以并发。整个设计利用二进制数作为索引,将哈希值的不同位段分别用于各层的寻址,配合桶的分裂合并极大提高了空间利用率。
3.1 Header Page
| max_depth_ (4B) | directory_page_ids_[512] (2048B) |
max_depth_:Header 能路由的最大深度,固定不变(目录数上限 =1 << max_depth_)directory_page_ids_:存储 Directory Page 的 page_id,初始全为INVALID_PAGE_ID,按需创建
关键方法:
// 用哈希值的高位路由到 directory
uint32_t HashToDirectoryIndex(uint32_t hash) const {
if (max_depth_ == 0) return 0;
return hash >> (sizeof(uint32_t) * 8 - max_depth_); // 取高 max_depth_ 位
}
3.2 Directory Page
| MaxDepth (4B) | GlobalDepth (4B) | LocalDepths[512] (512B) | BucketPageIds[512] (2048B) | Free (1528B) |
global_depth_:当前目录的全局深度,决定有效目录项数量2^global_depth_local_depths_[i]:每个目录槽对应桶的局部深度(uint8_t,节省空间)bucket_page_ids_[i]:目录槽指向的桶页面 ID
静态断言(编译期内存布局校验):
static_assert(sizeof(ExtendibleHTableDirectoryPage) ==
HTABLE_DIRECTORY_PAGE_METADATA_SIZE +
HTABLE_DIRECTORY_ARRAY_SIZE + // local_depths 数组
sizeof(page_id_t) * HTABLE_DIRECTORY_ARRAY_SIZE); // bucket_page_ids 数组
static_assert(sizeof(ExtendibleHTableDirectoryPage) <= BUSTUB_PAGE_SIZE);
这是一个很好的防御性编程技巧——在编译阶段保证结构体恰好能放进一个磁盘页(4096B),不依赖运行时检查。
关键方法:
// Split Image:将 bucket_idx 在第 local_depth 位取反,得到分裂后的另一个桶索引
uint32_t GetSplitImageIndex(uint32_t bucket_idx) const {
return bucket_idx ^ (1 << GetLocalDepth(bucket_idx));
}
// 目录扩展:将现有条目复制到 [i | (1 << old_global_depth)] 位置
void IncrGlobalDepth() {
for (uint32_t i = 0; i < Size(); ++i) {
SetBucketPageId(i | (1 << global_depth_), GetBucketPageId(i));
SetLocalDepth(i | (1 << global_depth_), GetLocalDepth(i));
}
++global_depth_;
}
IncrGlobalDepth 采用"增量扩展"策略:新的目录槽直接复制旧槽的内容(指向相同的 Bucket),而不是分配新页面,最小化分裂代价。
3.3 Bucket Page
| size_ (4B) | max_size_ (4B) | array_[...] (4088B) |
array_是std::pair<K, V>的紧凑数组,采用顺序存储(非链表)max_size_在Init()时由外部传入,取决于 KV 类型大小和页面大小
RemoveAt 的移位删除:
void RemoveAt(uint32_t bucket_idx) {
--size_;
for (uint32_t i = bucket_idx; i < size_; ++i) {
array_[i] = array_[i + 1]; // 向前移位填补空位
}
}
这是 O(n) 的移位删除,保持数组紧密排列,避免"空洞",查找时无需跳过已删条目。
4. 核心算法实现
当时的实现体会(Task 3): 这三个函数的实现是整个 Project 的核心,也花了最多时间。GetValue 是纯读操作,沿着 header → directory → bucket 的路径向下搜索,对应节点不存在则返回 false,逻辑较清晰。Insert 的难点在于桶满时的分裂:如果 global_depth 与 local_depth 相同,说明目录已经"用满",需要先 IncrGlobalDepth 把目录翻倍再做桶分裂;否则直接分裂桶、更新受影响的目录槽即可。分裂完后需要重新尝试插入,且由于分裂后数据按哈希重新分布,可能分裂一次还是不满足条件,因此要循环进行,直到达到最大深度或插入成功为止。Remove 的难点在于删除后桶为空时的合并:合并需要借助位运算判断 split image 桶的 local_depth 是否一致,否则不能合并;合并同样需要循环进行,直到无法继续合并为止。
4.1 查找(GetValue)
hash(key)
→ MSB → directory_idx → 检查是否 INVALID,否则 return false
→ 获取 Directory Page (ReadLock)
→ drop Header Read Lock(锁蟹行)
→ LSB → bucket_idx → 检查是否 INVALID,否则 return false
→ 获取 Bucket Page (ReadLock)
→ drop Directory Read Lock
→ Bucket::Lookup(key, value)
路径上的锁在"不再需要时立即释放",是 Latch Crabbing 在只读路径的体现。
4.2 插入(Insert)
正常路径(桶未满且 key 不存在):
hash(key) → 定位 directory → 定位 bucket → Bucket::Insert → return true
桶满触发分裂的完整流程:
Bucket::Insert 返回 false,且 key 不重复
→ 进入 while(SplitBucket(directory, bucket_idx)) 循环
↓
SplitBucket(directory, bucket_idx):
1. 检查 local_depth == directory_max_depth,若是则无法分裂,return false
2. new_bucket_idx = bucket_idx ^ (1 << local_depth) [GetSplitImageIndex]
3. 创建新 Bucket Page(NewPageGuarded)
4. 若 local_depth == global_depth,先 IncrGlobalDepth(目录翻倍)
5. new_local_depth = local_depth + 1
6. 更新所有指向 old bucket 和 new bucket 的目录槽:
for i in 0..(1 << (global_depth - new_local_depth)):
SetLocalDepth(old_bucket_idx + (i << new_local_depth), new_local_depth)
SetLocalDepth(new_bucket_idx + (i << new_local_depth), new_local_depth)
SetBucketPageId(old_bucket_idx + ..., old_bucket_page_id)
SetBucketPageId(new_bucket_idx + ..., new_bucket_page_id)
7. MigrateEntries:将 old bucket 中 hash 属于 new bucket 的条目迁移过去
→ return true
↓
分裂后重新计算 bucket_idx,尝试 Insert,成功则 return true,否则继续循环
MigrateEntries 的实现技巧:
void MigrateEntries(old_bucket, new_bucket, new_bucket_idx, local_depth_mask) {
uint32_t i = 0;
while (i < old_bucket->Size()) {
if ((Hash(key) & local_depth_mask) == new_bucket_idx) {
new_bucket->Insert(key, value, cmp_);
old_bucket->RemoveAt(i); // 删除后不递增 i,因为后面元素前移了
} else {
i++;
}
}
}
通过"删除后不递增 i"避免跳过条目,这是处理原地删除迁移的经典技巧。
4.3 删除(Remove)
正常路径(删除后桶非空):
hash(key) → 定位 bucket → Bucket::Remove → 若桶不为空,return true
桶空触发合并的完整流程:
Bucket::Remove 成功且桶变空
→ 进入 while(MergeBucket(directory, bucket_idx)) 循环
↓
MergeBucket(directory, bucket_idx):
1. 若 local_depth == 0,无法合并,return false
2. new_local_depth = local_depth - 1
3. idx = bucket_idx & ((1 << new_local_depth) - 1) [低 new_local_depth 位]
4. split_bucket_idx = bucket_idx ^ (1 << new_local_depth) [分裂对应桶]
5. 检查所有指向这两个桶的目录槽 local_depth 是否一致(防止非法合并)
6. 若当前桶空:将所有目录槽重定向到 split_bucket,设置 local_depth - 1
7. 若 split 桶空:将所有目录槽重定向到当前桶,设置 local_depth - 1
→ return true(合并成功)
↓
合并后,检查 CanShrink:所有 local_depth < global_depth → DecrGlobalDepth
继续尝试合并(可能出现连锁合并)
CanShrink 的判断逻辑:
bool CanShrink() {
if (global_depth_ == 0) return false;
for (uint32_t i = 0; i < 1 << global_depth_; ++i) {
if (GetLocalDepth(i) == global_depth_) return false; // 任意一个槽 LD == GD 则不能缩
}
return true;
}
5. 并发控制设计
当时的实现体会(Task 1): Task 1 实现三种 PageGuard 的构造函数、析构函数、operator= 和 Drop 函数,整体不难,但有两个细节需要注意。第一是锁不能重复释放,析构和 Drop 之前都需要先判断当前 guard 是否仍然有效;第二是一个让我当时感到困惑的设计:锁在 ReadPageGuard/WritePageGuard 外部(即在 BufferPoolManager 的获取函数中)获取,但在内部(析构/Drop 时)释放,这种"外取内放"的模式导致我一开始写出了 bug。事后反思,这样设计大概是为了让 PageGuard 的构造足够轻量,把锁的获取职责留给调用方。但个人认为如果把锁的获取也放在构造函数内会更符合 RAII 的语义、也更优雅。
5.1 PageGuard RAII 机制
三种 PageGuard 对应三种访问模式:
| 类型 | 锁类型 | 对应 BPM 方法 | 用途 |
|---|---|---|---|
BasicPageGuard | 无锁,仅 Pin | NewPageGuarded | 创建新页面 |
ReadPageGuard | 共享锁(RLatch) | FetchPageRead | 只读访问 |
WritePageGuard | 排它锁(WLatch) | FetchPageWrite | 读写访问 |
RAII 保证: Guard 析构时自动调用 UnpinPage(减引用计数)并释放锁,防止遗忘导致的死锁或内存泄漏。
Drop() 提前释放的技巧:
// 在 GetValue 中,读完 header 页面后立即释放,避免长时间持锁
header_page = nullptr; // 先置空指针,防止悬空使用
header_guard.Drop(); // 手动提前触发解锁+unpin
这是 Latch Crabbing 的实现形式:“抓住下一个锁之后,再释放上一个锁”。
5.2 Latch Crabbing(锁蟹行)算法
读操作(GetValue)的锁序列:
[RLock Header] → [RLock Directory] → [Drop Header RLock] → [RLock Bucket] → [Drop Directory RLock] → 读取 → [析构 Drop Bucket RLock]
写操作(Insert)的锁序列:
[WLock Header] → 若 directory 已存在: [Drop Header WLock] → [WLock Directory] → [WLock Bucket] → 操作
→ 若 directory 不存在: 持有 Header WLock 创建 Directory(InsertToNewDirectory)
关键约束: 必须先持有下层锁,再释放上层锁,避免另一个线程在"空窗期"修改页面结构导致当前线程读到脏数据。
5.3 加锁粒度分析
| 操作 | Header | Directory | Bucket |
|---|---|---|---|
| GetValue | RLock(早释放) | RLock(早释放) | RLock |
| Insert(不分裂) | WLock(早释放) | WLock(早释放) | WLock |
| Insert(分裂) | WLock(早释放) | WLock(全程) | WLock |
| Remove | WLock(早释放) | WLock(全程) | WLock |
Insert/Remove 在涉及结构修改(分裂/合并)时,Directory 的 WLock 全程持有直到操作完成,这是正确性的保证,但也是并发性能的瓶颈。
6. 设计
6.1 RAII PageGuard 模式
PageGuard 是 RAII(Resource Acquisition Is Initialization)模式的典型应用。通过将"持有锁 + Pin 页面"的生命周期绑定到栈上对象,从根本上避免了忘记释放锁或 Unpin 页面的 Bug。这在并发数据库系统中尤为重要——一旦页面没有被 Unpin,BPM 就无法驱逐它,最终导致所有线程阻塞。
6.2 静态断言保证页面布局
static_assert(sizeof(ExtendibleHTableDirectoryPage) <= BUSTUB_PAGE_SIZE);
使用 static_assert 在编译期验证结构体大小不超过磁盘页面大小(4096B),而非依赖运行时检查。这是一种零运行时开销的防御性编程技术。类似地,local_depths_ 使用 uint8_t(而非 uint32_t)节省了 1536B 空间,这是有意为之的紧凑设计。
6.3 MSB + LSB 分离路由
传统两层可扩展哈希只有 Directory,用哈希值的 LSB 路由。BusTub 在上层增加了固定大小的 Header Page,用 MSB 路由到对应的 Directory。
这个设计的好处:
- 扩展容量:总共可以存储
2^(header_max_depth + directory_max_depth)个桶 - 减少热点争用:不同高位前缀的 key 访问不同的 Directory,减少对单一目录页面的写锁竞争
- Header 固定大小:不像 Directory 会扩缩,Header 永远只有一页,是稳定的入口
6.4 Template 泛型设计
整个索引实现是 C++ 模板类 DiskExtendibleHashTable<K, V, KC>,通过显式模板实例化支持不同 key 大小:
template class DiskExtendibleHashTable<GenericKey<4>, RID, GenericComparator<4>>;
template class DiskExtendibleHashTable<GenericKey<8>, RID, GenericComparator<8>>;
// ... 16, 32, 64
GenericKey<N> 是一个固定大小的字节数组包装,配合 Schema 提取 Tuple 中对应列的字节表示。这种设计使同一套索引实现可以服务于不同长度的索引键,无需为每种类型重写代码。
6.5 IncrGlobalDepth 的增量复制
void IncrGlobalDepth() {
for (uint32_t i = 0; i < Size(); ++i) {
// 新槽 [i | (1 << global_depth_)] 复制旧槽 [i] 的内容
SetBucketPageId(i | (1 << global_depth_), GetBucketPageId(i));
SetLocalDepth(i | (1 << global_depth_), GetLocalDepth(i));
}
++global_depth_;
}
目录翻倍时,新增的那一半目录槽直接复制对应旧槽的 bucket page_id 和 local_depth,表示它们指向同一个桶。这避免了分配新桶和数据迁移,翻倍操作是 O(目录大小) 而非 O(数据量),代价非常小。
6.6 Adapter 模式(ExtendibleHashTableIndex)
ExtendibleHashTableIndex 继承自 Index 基类,将 DiskExtendibleHashTable 封装为数据库索引接口:
class ExtendibleHashTableIndex : public Index {
DiskExtendibleHashTable<KeyType, ValueType, KeyComparator> container_;
public:
bool InsertEntry(const Tuple &key, RID rid, Transaction *txn) override;
void DeleteEntry(const Tuple &key, RID rid, Transaction *txn) override;
void ScanKey(const Tuple &key, std::vector<RID> *result, Transaction *txn) override;
};
这是 **Adapter 模式(适配器模式)**的应用:DiskExtendibleHashTable 使用 GenericKey 作为键,而 Index 接口接收 Tuple。ExtendibleHashTableIndex 负责将 Tuple 转换为 GenericKey(通过 index_key.SetFromKey(key)),对上层透明。
思考
可扩展哈希的实现还是挺有意思的,三层结构设计与二进制位运算的结合让分裂合并逻辑优雅而紧凑。不过正如当初做完就意识到的,可扩展哈希的局限性太多:并发度受 Directory 写锁制约、哈希冲突无法从结构上解决、也基本没有深入优化的空间。
相比之下,B+ 树的应用更为广泛,结构也更复杂,学有余力的同学推荐去做一下其他年份的 B+ 树实现,对理解数据库索引原理会更有帮助。
附录:关键常量与内存布局速查
| 常量 | 值 | 含义 |
|---|---|---|
BUSTUB_PAGE_SIZE | 4096B | 磁盘页大小 |
HTABLE_DIRECTORY_MAX_DEPTH | 9 | Directory 最大深度(最多 512 个桶槽) |
HTABLE_DIRECTORY_ARRAY_SIZE | 512 | Directory 桶槽数量上限 |
header max_depth(默认) | - | 构造函数传入,通常为 4-9 |
bucket max_size(默认) | - | 由 Key/Value 类型大小决定 |
| 页面 | 总大小 | 关键字段 |
|---|---|---|
| Header Page | ≤4096B | max_depth(4) + directory_page_ids(2048) |
| Directory Page | 2572B | max_depth(4) + global_depth(4) + local_depths(512) + bucket_page_ids(2048) |
| Bucket Page | 4096B | size(4) + max_size(4) + array(4088) |