本文是对 CMU 15-445 BusTub Project1(Buffer Pool Manager)的回顾与延伸,涵盖 23fall 和 24fall 两个版本的实现经历、并发优化思路,以及以 Milvus CachingLayer 为例的工业级缓存池设计演变分析。
一、项目经历回顾
1.1 23fall Project1
从去年十月初到今年一月中旬,历时一个学期,在实验室的安排下,着手开始 CMU 15445 23fall 的数据库知识学习和 Project 的实现,终于在过年前完成所有的 Project。
Project1 整体还是比较简单的,大概在第一周就完成了全部内容,然后在 Project2 完成之后,花了一周的时间实现了代码优化。优化结果:LeaderBoard 排名第10(2025/1/27)
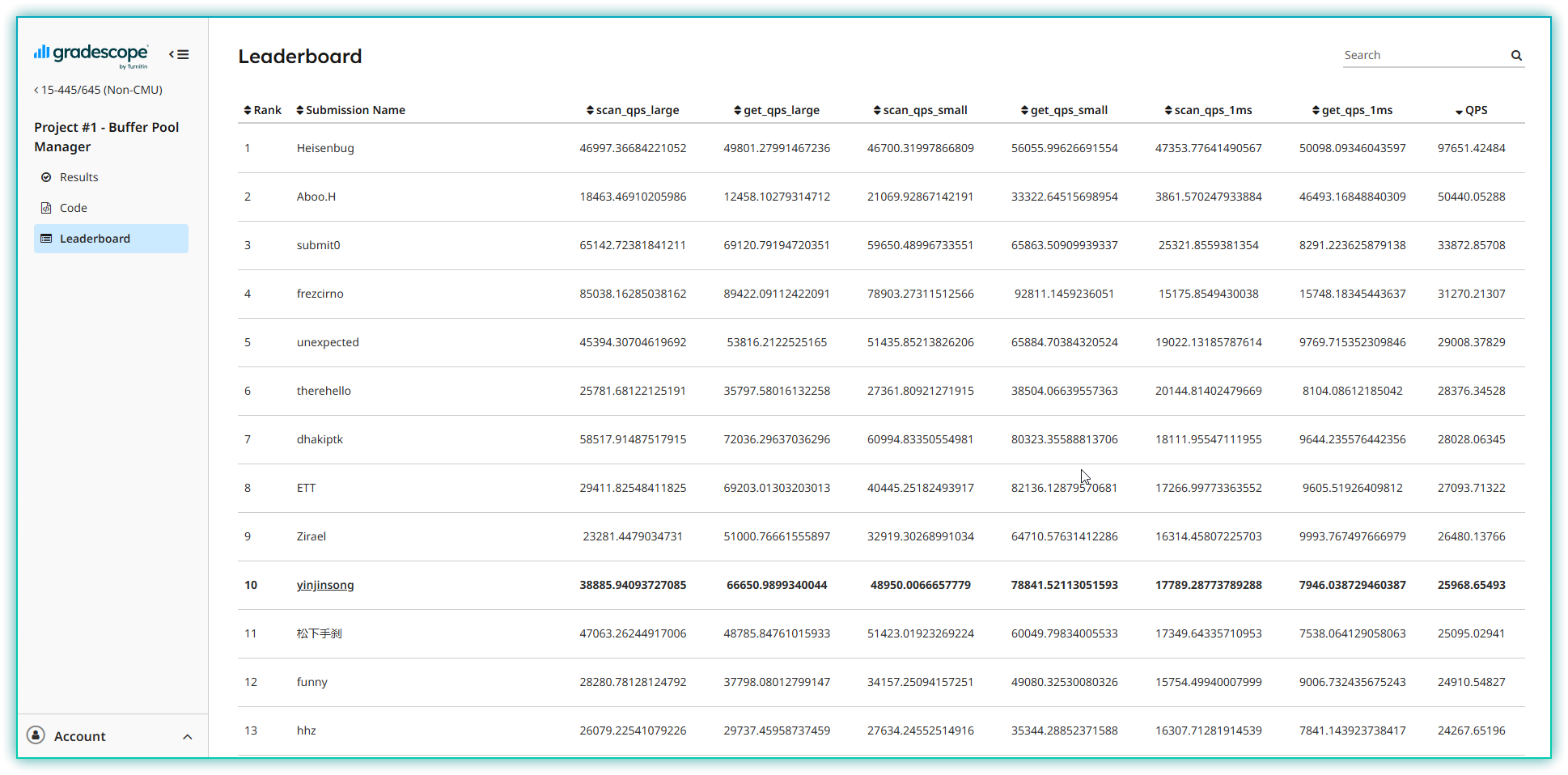
给前面几位神仙跪了,断层领先(有理由怀疑在 hack,各项数据太吓人了)。我的这个排名差不多就是我的极限了,能做到的都已经做了。
1.1.1 Task1 - LRU-K Replacement Policy
在 Task1 中需要使用 lru-k 策略实现内存页调度策略。每一个 frame 对应一个内存中的 page(数量有限),而在 BufferManager 中的 page 是实际存储数据的物理 page(相对无限)。
我的实现:
- 使用两个队列存放所有使用的 frame:
- 一个
history_list队列,存放访问次数少于 k 次的 frame,先进先出策略 - 一个
lru_list队列,存放所有访问次数大于等于 k 次的 frame,Evict 时顺序遍历求访问时间最小的 frame(lru_list的 Evict 为 O(n) 操作,但对 frame 的操作为 O(1))
- 一个
- lru-k 策略:
- 访问次数小于 K 次:不作更改(小于 K 频次时为 FIFO)
- 访问次数等于 K 次:将结点从
history_list_移动到lru_list_ - 访问次数大于 K 次:逐出结点中最早的访问记录,重新插入
lru_list
优化尝试:
- 尝试将
lru_list设置为有序,使 Evict 效率变为 O(1),但最终结果表明效率没有提升(可能是实现有问题,这部分代码已被删掉) - 利用
access_type属性,稍微调整 lru-k 的实现策略(LeaderBoard 开启了 16 个线程,8个随机读写,8个顺序读写),效率提升不少
1.1.2 Task2 - Disk Scheduler
这一部分比较简单,主要实现 Schedule 函数,将 IO 操作独立出去,放在单独的线程中执行 IO 操作。
优化:原本磁盘调度是单线程,将其修改为多线程。由于并发度不同,选择设置为动态线程池(开动态线程池貌似也没啥效率提升,LeaderBoard 测试太死了)。
1.1.3 Task3 - Buffer Pool Manager
综合 lru-k 内存调度策略和磁盘调度实现缓冲池管理,实现对物理页的透明访问。
实现内容:NewPage、FetchPage、UnPinPage、FlushPage、FlushAllPage、DeletePage。
我的并发实现思路:
- 刚开始为每一个使用的资源设置一个锁,遵守二阶段锁策略,尽量将各部分加锁部分分离
- 随着实现深入,理解了并发提升效率的本质:并发本质是将 IO 操作并发(这是可以并发的),其他 BufferPoolManager 属性加一把锁即可(多个线程都需要操作,基本没有并发可言)
- 最终结果:对 pages 外的所有数据使用一把大锁
latch_,对pages_使用锁数组(防止对同一个 page 操作并发冲突),遵循二阶段锁策略,将 IO 操作和对 bpm 字段操作分离开分别加锁,利用 IO 并发提高效率
1.2 24fall Project1
开学后便开始启动 24fall 的 bustub,主要是因为 23fall 缺少了 B+ 树的部分,来做 24fall 补上。
先说说 23 到 24 的变化,主要有以下几点:
- FrameHeader 替换 Page:23fall 的 Page 在 24fall 变成了 FrameHeader 并放到了
buffer_pool_manager文件中,底层的 Page 需要自己实现,自由度更高 - 删除 BasicPageGuard:只保留 ReadGuard 和 WriteGuard,保证从 BufferManager 中读取的页面必须加了读锁或写锁,这样实现了将加锁和解锁放在 ReadGuard 和 WriteGuard 中(好耶)
- 修改 NewPage 和 FetchPage 的分工:24fall 中 NewPage 只获取
page_id,所有页面读取放在 ReadPage 和 WritePage 中,这样只需实现一个 FetchPage,然后分别在 ReadPage 和 WritePage 中构建 ReadGuard 和 WriteGuard,获取页面只需写一个逻辑了(舒服了) - lru_k 小修改:Evict 返回
optional值,而不是原先通过指针和bool变量返回两个值,更合理的设计
总的来说,24fall 设计得比 23fall 更好了,自由度更高,并发也稍难了,因为 page 的读写需要自己实现。
LeaderBoard 排名第6(2025/03/07)
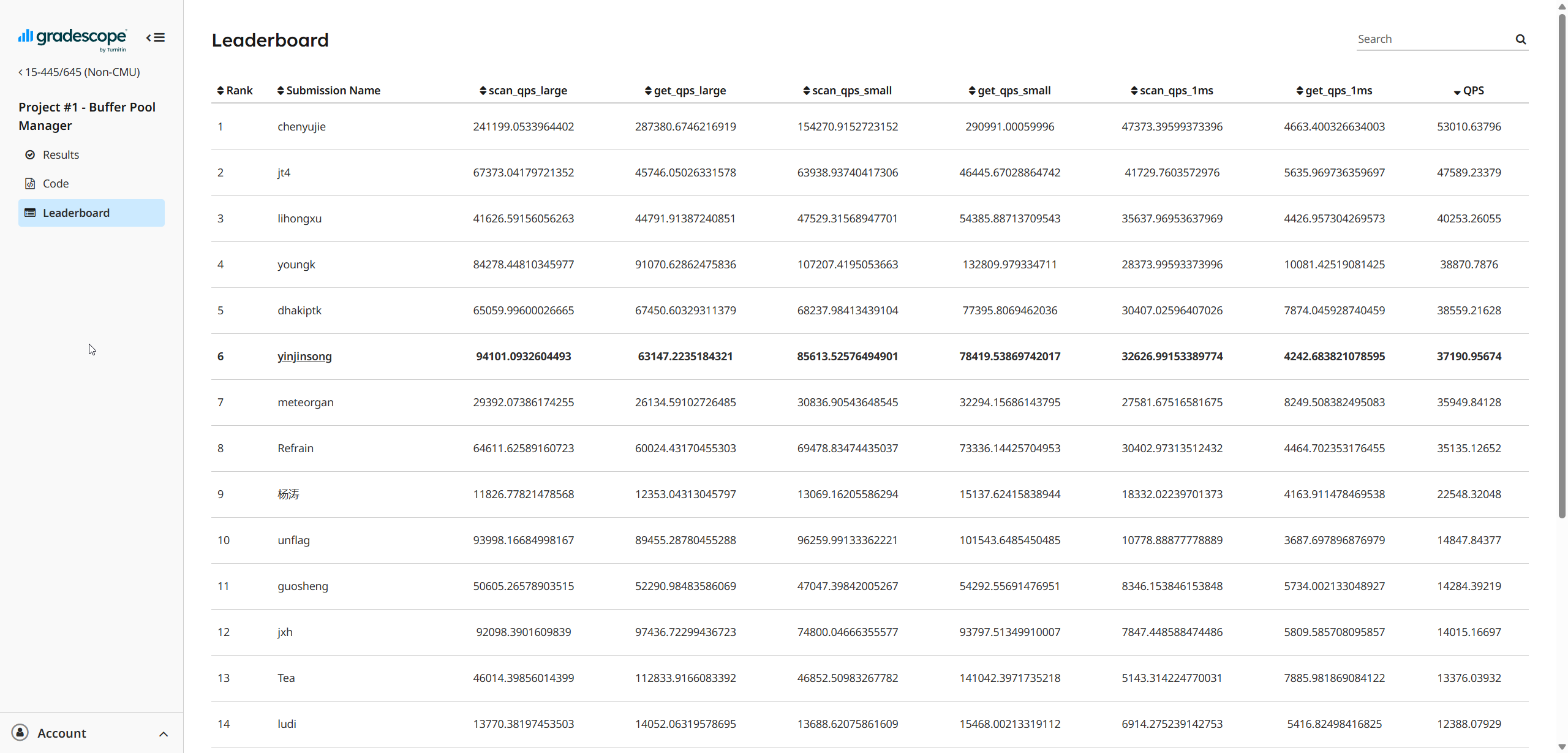
1.2.1 并发问题与解决过程
23fall 的并发思路(及其隐藏的错误)
23fall 中的思路:对所有线性执行部分加 bpm 锁,对 frame 的操作(有 IO 操作)根据 frame_id 加锁,保证每个 frame_id 的操作能独立执行。先获取 bpm 锁,再获取 frame 锁,然后释放 bpm 锁,最后释放 frame 锁,保证顺序执行不会被插队。
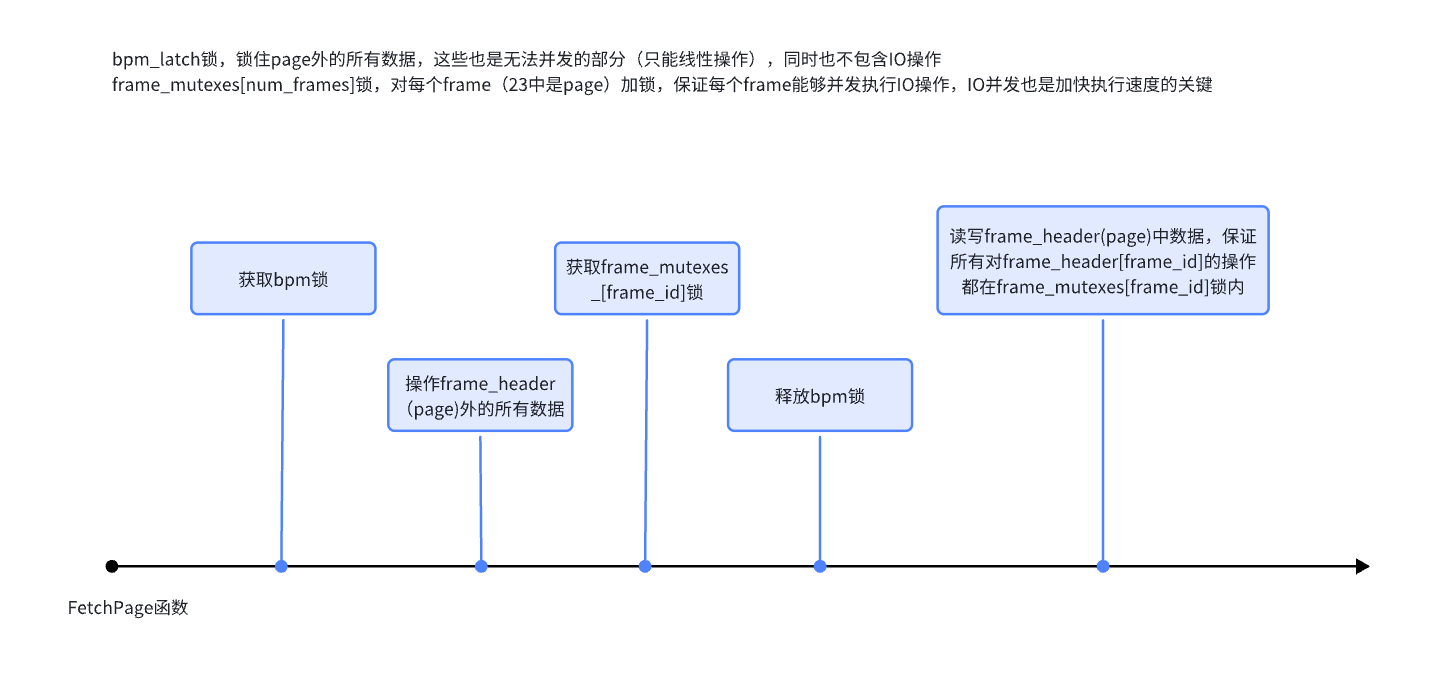
但这样写实际上还存在问题,只是在 23fall 中的测试没有测出来,在 24fall 中遇到了,折腾了好久。
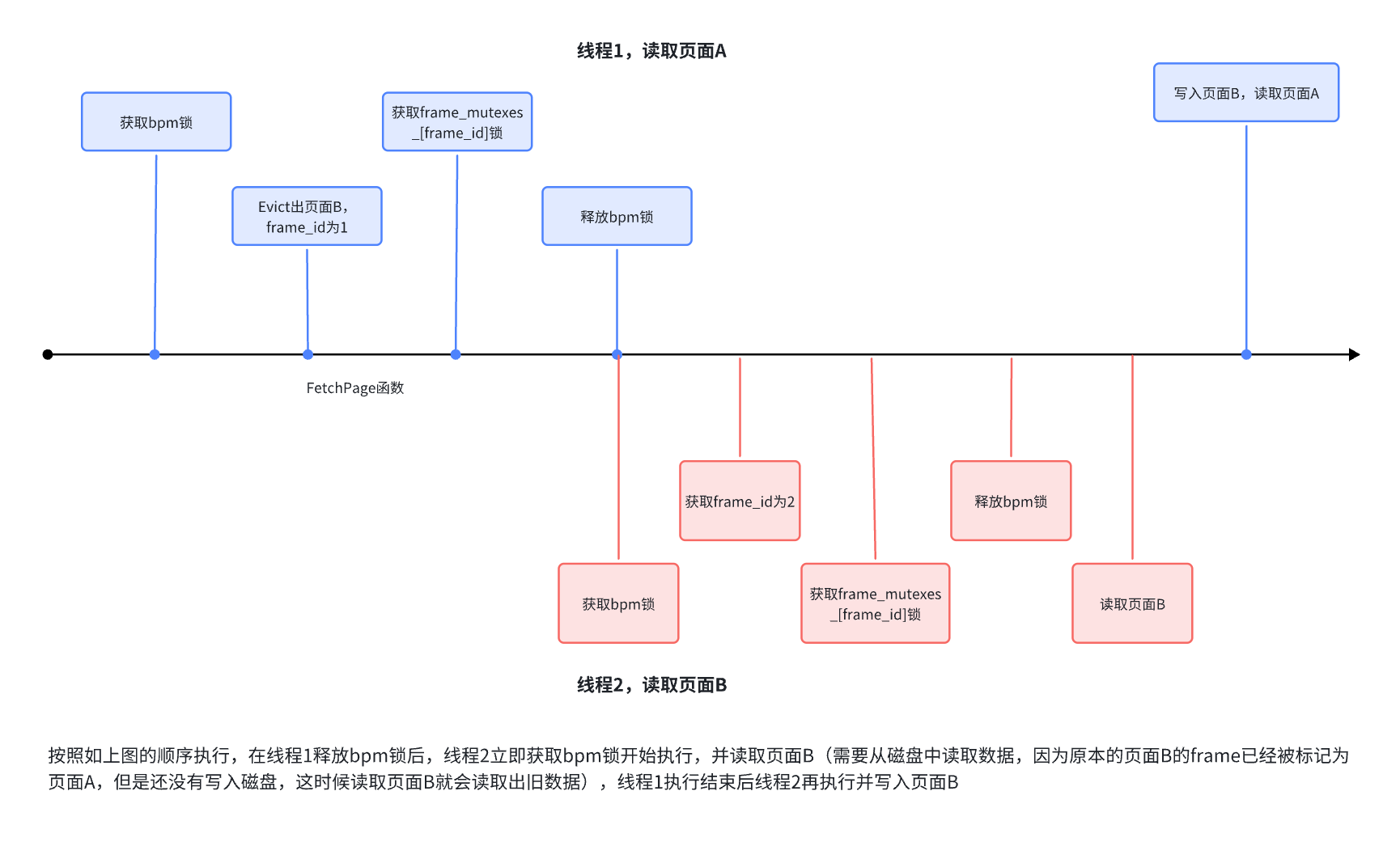
并发失败的原因:不能够保证 page 的顺序执行。
错误的尝试
有两种解决办法:
- 在线程1写入页面B后释放 bpm 锁,保证 page 读写的顺序执行,但并发度会大幅度下降
- 添加
page_mutexes_锁,对每一个 page 加锁,使用page_mutexes[page_id % 6400]获取 page 锁,获取 page 锁放在获取frames_mutexes锁之前
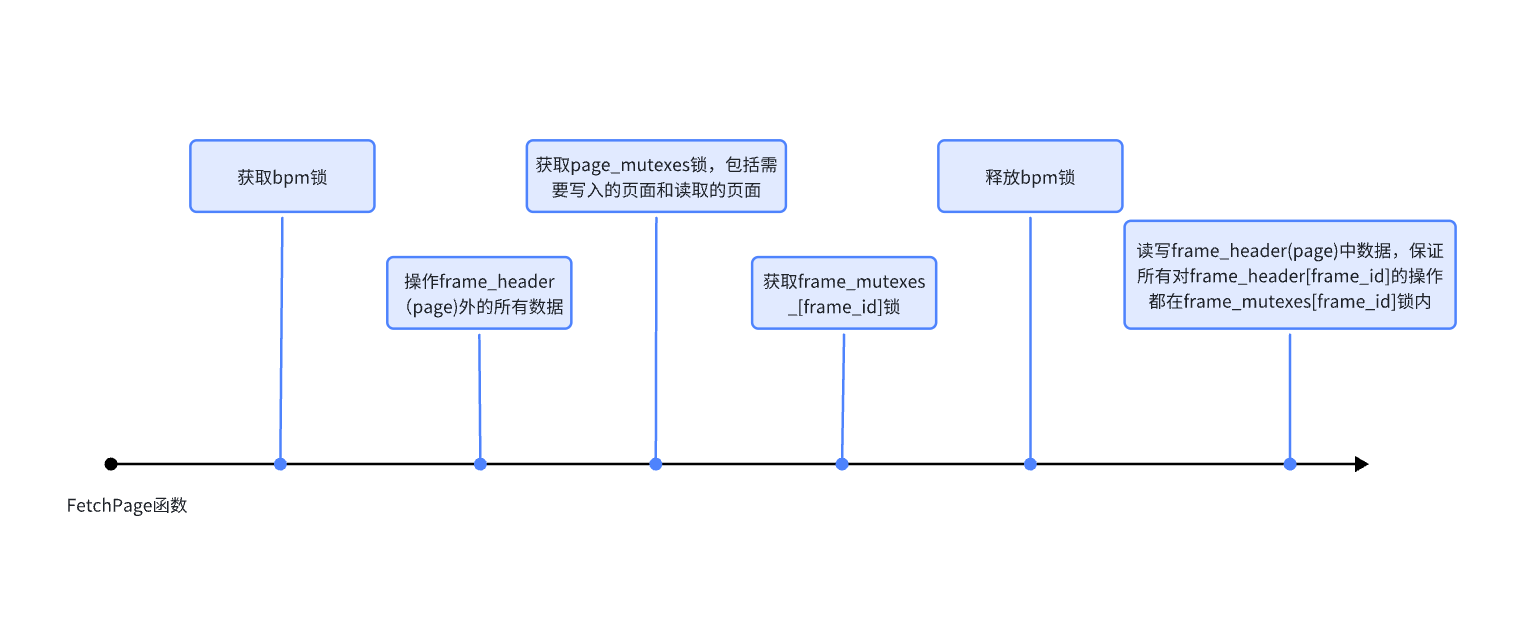
这个方法能通过 p1 的测试,但是在 p2 的测试中存在问题(获取 frame 锁后获取 page 锁失败,导致持有 bpm 锁和 frame 锁,其他线程无法执行,因为释放 PageGuard 需要获取 bpm 锁和 frame 锁)。
最终方案:引入条件变量
既然问题是写入和读取在并发时不能保证顺序执行,那就引入条件变量,在从内存中读取页面 A 之前判断是否有页面 A 的脏页面没有写入或正在写入。
在 BufferPoolManager 添加属性:
/** @brief A set of dirty pages that need to be flushed to disk. */
std::unordered_set<page_id_t> dirty_pages_;
/** @brief A mutex to protect the dirty pages set. */
std::mutex flush_mutex_;
/** @brief A condition variable to notify the flusher thread. */
std::condition_variable flush_cv_;
操作流程:
- FetchPage 获取新页面时,在释放
bpm_latch锁前,判断原本的 frame 是否是脏页,如果是就将其写入dirty_pages_中 - 释放
bpm_latch锁后进行脏页写入,成功写入后将对应page_id从dirty_pages_中删除,并使用notify_all唤醒等待线程 - 在读取页面之前,使用
flush_wait判断是否有脏页未写入,如果有就等待,释放flush_mutex_锁(不释放 frame 锁)
最终优化结果:
并发还是博大精深,先入为主地认为原本的设计是正确的,折腾了太久(沉默)。
二、BusTub 缓存池深度解析
在分析工业级设计之前,先把 BusTub 的每个组件彻底吃透,这样后面的演变才有对照的基础。
2.1 整体架构与组件关系
BusTub 的缓存池由三个组件构成,各司其职:
上层 (B+ Tree, SQL Executor 等)
↓ CheckedReadPage / CheckedWritePage
┌──────────────────────────────┐
│ BufferPoolManager │
│ ┌─────────┐ ┌────────────┐ │
│ │page_table│ │free_frames │ │ ← 内存管理
│ └─────────┘ └────────────┘ │
│ ┌──────────────────────────┤
│ │ LRUKReplacer │ ← 驱逐决策
│ └──────────────────────────┤
│ ┌──────────────────────────┤
│ │ DiskScheduler │ ← 异步 I/O
│ └──────────────────────────┤
└──────────────────────────────┘
↓ ReadPage / WritePage
磁盘文件 (DiskManager)
三者的职责分工:
LRUKReplacer:只负责"选谁被驱逐"——维护访问历史,决定淘汰顺序BufferPoolManager:负责"内存帧的分配与映射"——哪个物理帧存哪个逻辑页DiskScheduler:负责"把 I/O 请求异步化"——不让读写磁盘阻塞主线程
2.2 LRU-K Replacer 详解
为什么需要 LRU-K?
普通 LRU 只记录"最近一次访问时间",容易被顺序扫描(Sequential Scan)污染:全表扫描时,每个页只访问一次,但它们会把真正的热页挤出内存。
LRU-K 的核心思想:只有访问次数达到 K 次的页,才算真正"热"。访问次数不足 K 次的页,使用 FIFO 策略——先进先出,谁最早进来就先被驱逐。
双队列实现(2Q 策略)
BusTub 实现的是一种 2Q(Two Queue) 变体:
// 来自 lru_k_replacer.h
std::list<frame_id_t> history_list_; // 历史队列:访问次数 < k 的页,FIFO 淘汰
std::list<frame_id_t> cache_list_; // 缓存队列:访问次数 >= k 的页,LRU 淘汰
LRUKNode 的数据结构:
class LRUKNode {
std::list<size_t> history_; // 时间戳历史(最多保留 k 个)
bool is_evictable_{false}; // 是否可被驱逐(pin_count == 0 时才为 true)
std::list<frame_id_t>::iterator pos_; // 指向所在链表中的位置,O(1) 删除
};
pos_ 是链表迭代器,这是一个重要的优化:std::list 的迭代器在插入/删除其他元素时不会失效,所以可以提前保存迭代器,在需要删除时直接 list.erase(pos_),时间复杂度 O(1)。
RecordAccess 的状态转换逻辑
void LRUKReplacer::RecordAccess(frame_id_t frame_id, AccessType access_type) {
auto &node = node_store_[frame_id];
node.history_.push_back(current_timestamp_++);
if (node.history_.size() == 1) {
// Case 1:首次访问,进入 history_list_(从头部插入)
history_list_.push_front(frame_id);
node.pos_ = history_list_.begin();
}
else if (node.history_.size() == k_) {
// Case 2:达到 k 次,晋升到 cache_list_
history_list_.erase(node.pos_);
cache_list_.push_front(frame_id);
node.pos_ = cache_list_.begin();
}
else if (node.history_.size() > k_) {
// Case 3:已在 cache_list_,LRU 更新(移到头部,并丢弃最旧时间戳)
node.history_.pop_front(); // 只保留最近 k 个时间戳
cache_list_.erase(node.pos_);
cache_list_.push_front(frame_id);
node.pos_ = cache_list_.begin();
}
}
状态转换图:
首次访问 → [history_list_ 头部]
↓ 第 k 次访问
[cache_list_ 头部] ←→ 每次访问后移到头部(LRU)
Evict 的优先级逻辑
auto LRUKReplacer::Evict() -> std::optional<frame_id_t> {
// 优先从 history_list_ 尾部驱逐(访问次数不足 k,且是最早进入的)
if (evict_from_list(history_list_)) return frame_id;
// 其次从 cache_list_ 尾部驱逐(最久未访问的"热页")
if (evict_from_list(cache_list_)) return frame_id;
return std::nullopt;
}
关键点:evict_from_list 从链表尾部扫描(反向迭代器),找第一个 is_evictable_ == true 的节点。链表头部是最近访问的,尾部是最久没访问的。
2.3 BufferPoolManager 详解
核心数据结构
class BufferPoolManager {
// 物理内存帧(固定数量,启动时分配完毕)
std::vector<std::shared_ptr<FrameHeader>> frames_;
// 页 ID → 帧 ID 的映射表(类似 OS 的页表)
std::unordered_map<page_id_t, frame_id_t> page_table_;
// 空闲帧列表(没有存放任何页的帧)
std::list<frame_id_t> free_frames_;
// 脏页集合(需要写回磁盘的页)
std::unordered_set<page_id_t> dirty_pages_;
// 驱逐器(LRU-K)
std::shared_ptr<LRUKReplacer> replacer_;
// 磁盘调度器
std::unique_ptr<DiskScheduler> disk_scheduler_;
};
FrameHeader 的结构:
class FrameHeader {
frame_id_t frame_id_; // 帧编号
page_id_t page_id_; // 当前存放的页 ID
std::atomic<size_t> pin_count_; // 引用计数(多少个线程在使用)
bool is_dirty_; // 是否被修改(需要写回磁盘)
std::vector<char> data_; // 实际数据(4KB)
std::shared_mutex rwlatch_; // 读写锁(供 PageGuard 使用)
};
FetchPage 的完整流程
FetchPage 是 BPM 的核心函数,理解它就理解了 BPM 的全部逻辑:
FetchPage(page_id)
│
├── 命中?(page_table_ 中存在)
│ ↓ YES
│ RecordAccess + SetEvictable(false) + pin_count_++
│ 直接返回 frame
│
└── 未命中?
│
├── free_frames_ 非空?
│ ↓ YES
│ 从 free_frames_ 取一个空闲帧
│
└── free_frames_ 为空?
↓ YES
replacer_->Evict() 选出受害者帧
│
├── 受害者帧是脏页?
│ ↓ YES
│ 先写回磁盘(DiskScheduler 同步等待)
│
└── 从磁盘读取目标页到帧
RecordAccess + SetEvictable(false) + pin_count_++
返回 frame
Pin 机制详解
pin_count_ 是防止"正在使用的页被驱逐"的关键机制:
pin_count_ > 0:页面正在被某个线程使用,不能被驱逐pin_count_ == 0:页面空闲,可以被驱逐
// 获取页时:pin_count_ 增加,SetEvictable(false)
++frames_[frame_id]->pin_count_;
replacer_->SetEvictable(frame_id, false);
// 用完(PageGuard 析构)时:pin_count_ 减少,SetEvictable(true)
--frames_[frame_id]->pin_count_;
if (frames_[frame_id]->pin_count_ == 0) {
replacer_->SetEvictable(frame_id, true);
}
问题:BusTub 中,pin_count_ 需要上层调用者手动管理(通过 PageGuard 的 RAII 析构)。如果忘记释放 Guard,帧永远无法被驱逐,最终导致 BPM 耗尽内存。
脏页(Dirty Page)管理
写操作不会立即写磁盘(Write-Back 策略):
- 修改帧内数据,标记
is_dirty_ = true - 只有在驱逐该帧或显式调用 FlushPage时,才写回磁盘
这是数据库缓存的标准策略,避免每次写操作都触发磁盘 I/O。
2.4 DiskScheduler 详解
生产者-消费者模型
DiskScheduler 使用经典的生产者-消费者模式,将 I/O 请求与执行解耦:
class DiskScheduler {
std::queue<std::function<void()>> tasks_; // 任务队列
std::vector<std::thread> workers_; // 工作线程池
std::mutex queue_mutex_; // 保护任务队列
std::condition_variable condition_; // 通知工作线程
bool stop_ = false; // 停止信号
};
Schedule 函数(生产者):
void DiskScheduler::Schedule(DiskRequest r) {
auto request = std::make_shared<DiskRequest>(std::move(r));
{
std::unique_lock<std::mutex> lock(queue_mutex_);
tasks_.emplace([this, request = std::move(request)]() mutable {
// 实际的磁盘读/写操作
if (request->is_write_) {
disk_manager_->WritePage(request->page_id_, request->data_);
} else {
disk_manager_->ReadPage(request->page_id_, request->data_);
}
request->callback_.set_value(true); // 通知调用者完成
});
}
condition_.notify_one(); // 唤醒一个工作线程
}
StartWorkerThread(消费者):
void DiskScheduler::StartWorkerThread() {
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(queue_mutex_);
condition_.wait(lock, [this] { return !tasks_.empty() || stop_; });
if (stop_ && tasks_.empty()) return;
task = std::move(tasks_.front());
tasks_.pop();
}
task(); // 锁外执行,不阻塞其他线程取任务
}
}
std::promise / std::future —— 同步等待异步结果
BusTub 使用 std::promise<bool> 和 std::future<bool> 实现"提交请求后等待完成":
// 调用方:
auto promise = disk_scheduler_->CreatePromise(); // std::promise<bool>
auto future = promise.get_future(); // std::future<bool>
disk_scheduler_->Schedule({false, data_ptr, page_id, std::move(promise)});
future.get(); // 阻塞等待工作线程调用 promise.set_value(true)
概念解释:
std::promise<T>:一端写入结果(set_value())std::future<T>:另一端等待结果(get()阻塞直到有结果)- 两者是配对的"通信信道",适合"一次性事件通知"
局限性:future.get() 会阻塞当前线程。虽然 I/O 操作在工作线程中异步执行,但调用方线程仍然需要等待。这在高并发场景下会成为瓶颈。
2.5 BusTub 设计的局限性
BusTub 的设计目的是教学,为了简洁清晰做了很多简化,这些简化在工业环境中都会遇到问题:
| 局限性 | 具体问题 | 工业影响 |
|---|---|---|
| 固定 4KB 粒度 | 所有数据必须以 4KB 页为单位管理 | 向量索引一个文件可能几十GB,以4KB分页管理开销极大 |
| 全局大锁 | bpm_latch_ 保护所有操作,同一时间只有一个线程能操作BPM | 高并发查询时严重竞争,吞吐量无法水平扩展 |
| 同步阻塞 I/O | future.get() 阻塞线程等待磁盘读完 | 磁盘延迟 ms 级,线程被白白占用 |
| 硬编码 DiskManager | 只能从本地磁盘读页,无法接入 S3/HDFS 等远端存储 | 云原生场景无法使用 |
| 手动 Pin/Unpin | 调用者需要记住 unpin,否则内存泄漏 | 复杂查询调用链中容易出错 |
| 只有内存一种存储 | 要么在内存,要么在磁盘,没有中间层 | 无法利用 mmap、大页内存等 OS 特性 |
| 无资源预约 | 加载数据时不提前声明用量,可能加载中途OOM | 生产系统不可接受 |
| 无物理内存感知 | 只管逻辑帧数,不关心实际物理内存压力 | 容器环境内存超售时会OOM |
这些局限性就是 Milvus CachingLayer 要一一解决的问题。
三、技术演变:8个核心维度(以 Milvus 为例)
演变 1:数据管理粒度
BusTub(固定4KB页):
磁盘文件:[Page 0][Page 1][Page 2]...
4KB 4KB 4KB
内存帧: [Frame 0][Frame 1]...
4KB 4KB
所有数据必须是 4KB 的倍数。读取 100 字节的数据,也要把整个 4KB 页加载进内存。
Milvus(可变粒度 Cell):
磁盘: [Parquet 文件: Row Group 0][Row Group 1][Row Group 2]...
不固定大小,由列数据决定
内存: [CacheCell 0][CacheCell 1][CacheCell 2]...
大小由 Translator.estimated_byte_size_of_cell() 决定
Milvus 的"Cell"对应 BusTub 的"Page",但大小完全由业务数据决定。一个 Cell 可能是:
- 一个 Parquet RowGroup(几十MB)
- 一个向量索引分片(几GB)
- 一个倒排索引的 term 词典
这个演变的意义:数据库页大小固定是因为需要随机寻址(B+ 树靠页偏移定位)。向量数据库的访问模式是"给我整个列段",不需要按固定大小寻址,可变粒度更自然。
关键接口:Translator::estimated_byte_size_of_cell(cid_t cid) 告诉框架每个 Cell 的大小,而不是框架自己假设所有 Cell 一样大。
演变 2:替换算法
BusTub(LRU-K 双队列):
history_list_: [新页] → ... → [最老的新页] ← 从尾部驱逐
cache_list_: [最近访问] → ... → [最久未访问] ← 从尾部驱逐
LRU-K 解决了顺序扫描污染问题。但在高并发场景下有一个新问题:每次 unpin 都要把节点移到链表头部,这需要对整个链表加锁。
Milvus(LRU + Touch Window 优化):
Milvus 的 DList 也是 LRU 双向链表,但增加了 Touch Window 机制:
void touchItem(ListNode* node, ...) {
auto now = steady_clock::now();
// 如果距上次 touch 时间 < touch_window,跳过不更新
if (now - node->last_touch_ < eviction_config_.cache_touch_window) {
return;
}
// 超过时间窗口才真正移到链表头部
node->last_touch_ = now;
moveToHead(node); // 需要对链表加锁
}
为什么这个优化重要?
假设有 1000 个查询线程并发访问同一个热点 Cell,每次访问结束(unpin)都要把 Cell 移到 LRU 链表头部。没有优化的情况下,1000 次 moveToHead 操作都要争抢链表锁,形成严重的锁竞争。
有了 Touch Window(比如 1 秒),这 1000 次操作中,只有第一次会真正移动节点,其余 999 次直接跳过。链表锁竞争从 1000 次降到约 1 次(每秒)。
对比总结:
| 特性 | BusTub LRU-K | Milvus DList |
|---|---|---|
| 算法 | 双队列 2Q | 单 LRU 链表 |
| 每次访问更新链表? | 是 | 有时间窗口限制 |
| 链表锁竞争 | 高(每次unpin都要加锁) | 低(窗口内跳过) |
| try_lock 驱逐 | 否(驱逐时会阻塞) | 是(跳过正在被用的节点) |
演变 3:I/O 模型
BusTub(同步 Promise-Future):
// BusTub 调用方:提交请求后阻塞等待
auto promise = disk_scheduler_->CreatePromise();
auto future = promise.get_future();
disk_scheduler_->Schedule({...promise...});
future.get(); // ← 线程被阻塞在这里,等磁盘 I/O 完成
线程关系:
调用线程: ────[提交请求]────[future.get() 阻塞]────────────[继续执行]
工作线程: [读磁盘] → [promise.set_value()]
虽然 I/O 发生在工作线程,但调用线程仍然被占用等待,浪费了 CPU 资源。
Milvus(Folly 异步 Future):
// Milvus 调用方:获取 Future,可以去做别的事
folly::SemiFuture<NodePin> future = cell->pin().second;
// ...可以先处理其他 cell...
// 最终统一等待所有 Future
auto all_pins = SemiInlineGet(folly::collect(futures));
线程关系(完全异步时):
调用线程: ─[提交加载]─[去做其他事情]─────────────────[collect 等待]─[继续]
加载线程: [读磁盘...] → [SharedPromise.fulfill()]
关键区别:folly::SharedPromise
BusTub 的 std::promise 只能有一个 future。但 Milvus 用 folly::SharedPromise,允许多个等待者等待同一个结果:
线程A: cell->pin() → 返回 SemiFuture(等待加载完成)
线程B: cell->pin() → 返回 SemiFuture(复用同一个 SharedPromise!)
线程C: cell->pin() → 返回 SemiFuture(同上)
加载线程:只执行一次 get_cells(),fulfill SharedPromise → 线程A/B/C 同时唤醒
这避免了重复加载:多个线程同时需要同一个 Cell,不会各自去读一遍磁盘,只读一次,大家共享结果。BusTub 没有这个机制(因为它是教学项目,通常假设单个上层操作),工业环境中必须处理这种并发。
演变 4:资源管理
BusTub(隐式,按帧数限制):
BusTub 的内存限制非常简单:最多 num_frames 个帧,每帧 4KB,总内存 = num_frames * 4KB。
问题:
- 不知道"加载中"的数据占用多少内存(加载过程中可能需要临时内存)
- 同时发起 100 个加载请求时,可能总共需要 100 * 4KB * 2 的临时内存,但只检查最终的
num_frames限制
Milvus(显式预约机制 + 双水位控制):
资源预约(Reserve-Charge-Refund)
加载前:ReserveLoadingResourceWithTimeout(estimated_loading_size)
→ total_loading_size_ += estimated_size ← 预约:先声明占用
加载中:translator_->get_cells() ← 实际 I/O
加载完:ChargeLoadedResource(actual_loaded_size)
→ total_loaded_size_ += actual_size ← 计费:正式计入
→ RAII: ReleaseLoadingResource()
→ total_loading_size_ -= estimated_size ← 释放预约
驱逐时:RefundLoadedResource(evicted_size)
→ total_loaded_size_ -= evicted_size ← 退款:归还资源
这个三步流程保证在任何时刻都能知道:
- 已加载数据:
total_loaded_size_ - 正在加载数据:
total_loading_size_ - 总内存压力:两者之和
加载前就声明,防止所有线程同时开始加载,导致超出内存上限。
双水位控制
内存使用量
│
100%├────────────────────────────── max_resource_limit_ (拒绝新请求)
│
80%├────────────────────────────── high_watermark_(后台主动驱逐)
│ ↑ 触发异步驱逐,目标:降到低水位
60%├────────────────────────────── low_watermark_(驱逐停止目标)
│
0%└──────────────────────────────
为什么需要两个水位,而不是一个阈值?
如果只有一个阈值(比如 80% 触发驱逐),会产生"抖动":
- 内存 80% → 触发驱逐 → 降到 79% → 停止驱逐 → 新数据进来 → 又到 80% → 再驱逐…
每次驱逐一点点,频繁触发驱逐逻辑,产生大量开销。
有了双水位:
- 超过高水位(80%)→ 触发驱逐,目标降到低水位(60%)
- 一次驱逐 20% 的数据,很长时间内不需要再驱逐
- 提供了"缓冲带",减少频繁抖动
类比:空调的制冷设定点。如果把目标温度设为 26°C,空调不会在 26.1°C 开、26.0°C 关(这样会频繁启停)。实际上是"高于 28°C 开,低于 24°C 关",即双水位。
物理内存感知
Milvus 还额外检测真实物理内存使用率:
bool DList::checkPhysicalMemoryLimit() {
// 通过读取 /proc/meminfo 获取系统实际内存使用率
auto usage_ratio = getSystemMemoryUsageRatio();
return usage_ratio > overloaded_memory_threshold_percentage;
}
即使逻辑配额(max_resource_limit_)未超,如果物理内存已经很紧张(比如容器内存超售),也会触发驱逐。BusTub 完全不关心物理内存,只关心帧数——这在容器化环境中很危险。
演变 5:并发控制
BusTub(全局大锁):
// BPM 几乎所有操作都先加这把锁
std::unique_lock<std::mutex> latch_lock(*bpm_latch_);
影响:同一时刻只有一个线程能进行 FetchPage、DeletePage 等操作。10 个查询线程只有 1 个在工作,9 个在等锁。
Milvus(分层细粒度锁策略):
层次 1:DList::list_mtx_ (std::mutex)
保护:链表结构、total_loaded_size_、waiting_requests_
持锁时间:短(只做链表操作)
层次 2:ListNode::mtx_ (std::shared_mutex)
保护:每个 Cell 的状态机转换
读操作:shared_lock(多读者并行)
写操作:unique_lock(独占)
关键优化:tryEvict 中的 try_lock
驱逐路径是最容易和业务路径冲突的地方。BusTub 中驱逐操作和正常访问共享同一把锁,会互相阻塞。
Milvus 的驱逐路径使用 try_lock:
// tryEvict 遍历链表时:
auto& lock = item_locks.emplace_back(node->mtx_, std::try_to_lock);
if (!lock.owns_lock()) {
item_locks.pop_back();
continue; // 这个节点正在被访问,跳过它,找下一个候选
}
效果:驱逐线程永远不会阻塞业务查询线程。驱逐时遇到"锁被业务线程持有"的节点,直接跳过找下一个候选,而不是等待。最坏情况下驱逐线程跳过很多节点,但它绝不会让正在服务的查询变慢。
std::shared_mutex 读写锁:对于 pin_count 的检查(读操作),使用 shared_lock,多个驱逐线程可以同时读取状态而不互相阻塞;只有状态转换(写操作)才使用 unique_lock。
演变 6:数据加载策略
BusTub(硬编码 DiskManager):
// DiskScheduler 只会调用 DiskManager 的两个函数
disk_manager_->WritePage(request->page_id_, request->data_);
disk_manager_->ReadPage(request->page_id_, request->data_);
加载逻辑完全固定:从本地磁盘按页 ID 读写 4KB 数据。无法扩展到其他存储介质或数据格式。
Milvus(策略模式 Translator):
// 纯虚接口:业务代码实现"如何加载",框架控制"何时加载"
template <typename CellT>
class Translator {
public:
// 告诉框架:总共有多少个 Cell
virtual size_t num_cells() const = 0;
// 告诉框架:给定行号,对应哪个 Cell
virtual cid_t cell_id_of(uid_t uid) const = 0;
// 告诉框架:这个 Cell 有多大(加载前和加载中的估算)
virtual std::pair<ResourceUsage, ResourceUsage>
estimated_byte_size_of_cell(cid_t cid) const = 0;
// 真正执行加载:框架在需要时调用,业务代码决定从哪里、怎么加载
virtual std::vector<std::pair<cid_t, std::unique_ptr<CellT>>>
get_cells(OpContext* ctx, const std::vector<cid_t>& cids) = 0;
};
为什么这个设计优雅?
对比一下:
BusTub 的思路:
框架:我来读磁盘
业务:我也要读磁盘?那改框架代码吧
Milvus 的思路:
框架:我来决定什么时候加载、加载多少、何时驱逐
业务:我来决定如何加载(从 S3?本地?Parquet 格式?向量索引格式?)
这是控制反转(IoC):框架不调用业务代码的具体逻辑,而是提供接口,让业务代码来"填空"。
实际上,Milvus 中不同数据类型有不同的 Translator:
ChunkTranslator:加载 Parquet 列数据(标量字段)VectorIndexTranslator:加载 HNSW/IVF 向量索引InvertedIndexTranslator:加载倒排索引(用于标量过滤)
三者共享同一个 CachingLayer 框架,只需各自实现 Translator 接口。
可选的预取(Bonus Cells):
// Translator 可以声明"如果要加载这些 cells,顺便也把相邻的也加进来"
virtual std::vector<cid_t>
bonus_cells_to_be_loaded(const std::vector<cid_t>& cids) const {
return {}; // 默认不预取
}
这类似于操作系统的预读(Read-Ahead):顺序读取时提前加载后续页面,利用局部性原理减少未来的 I/O。BusTub 没有这个概念,因为教学环境通常不考虑 I/O 优化。
演变 7:Pin 机制
BusTub(手动管理,Guard 辅助):
// BusTub 的 PageGuard 析构时 unpin
class ReadPageGuard {
~ReadPageGuard() {
if (frame_ != nullptr) {
--frame_->pin_count_;
if (frame_->pin_count_ == 0) {
replacer_->SetEvictable(frame_id_, true);
}
}
}
};
虽然用了 RAII(Guard 析构时自动 unpin),但 pin 的生命周期和 Guard 对象绑定。如果上层代码把 Guard 存进一个容器,或者在不同线程之间传递,很容易出现生命周期管理错误。
Milvus(NodePin + PinWrapper 双层 RAII):
// 第一层:NodePin 管理单个 Cell 的 pin 状态
class NodePin {
ListNode* node_;
public:
NodePin(NodePin&&) noexcept; // 只允许移动,不允许复制
NodePin(const NodePin&) = delete; // 复制 = pin_count 计数错误
~NodePin() { if (node_) node_->unpin(); } // 析构自动 unpin
};
为什么禁止复制?如果允许复制,两个 NodePin 对象指向同一个节点,析构两次,pin_count 会减 2 而不是 1,导致计数错误,节点可能被提前驱逐。
// 第二层:PinWrapper<T> 把 pin 生命周期与业务数据指针绑定
template <typename T>
class PinWrapper {
std::shared_ptr<CellAccessor<CellT>> ca_; // 内部持有 NodePin(集合)
T data_; // 指向 Cell 内数据的指针
public:
T& operator*() { return data_; }
T* operator->() { return &data_; }
// 析构时:ca_ 析构 → NodePin 析构 → unpin()
};
使用方式:
// 上层代码:完全感知不到 pin 机制
auto pw = column->DataOfChunk(op_ctx, chunk_id);
// pw 是 PinWrapper<const char*>,直接当指针用
for (int i = 0; i < size; i++) {
process(pw[i]);
}
// pw 退出作用域 → 自动 unpin → Cell 可以被驱逐
对比 BusTub:BusTub 的 PageGuard 还需要上层知道"我在用一个 Guard",PinWrapper 则把这个细节完全隐藏——上层代码只是使用一个"看起来像指针的东西",完全不知道缓存的存在。
skip_pin_ 快速路径:
当某些数据被标记为"永远不驱逐"(如常驻内存的向量索引),预热完成后设置 skip_pin_ = true:
auto future = slot->PinCells(op_ctx, {cid});
// 内部逻辑:
if (skip_pin_.load(std::memory_order_relaxed)) {
return immediately_without_lock; // 完全绕过锁和引用计数
}
对于热路径(每秒数百万次查询),完全绕过锁操作能带来显著的性能提升。BusTub 所有操作都要加锁,没有这样的优化空间。
演变 8:存储层次
BusTub(单层 DRAM):
[DRAM 帧] ↔ [本地磁盘文件]
只有两层:内存中(DRAM)或磁盘上(本地文件)。
Milvus(多层存储支持):
[DRAM(CachingLayer)] ↔ [本地磁盘(CachingLayer)]
↕ ↕
[mmap 映射文件(MmapChunkManager)]
↕
[远端存储:S3 / MinIO / HDFS(通过 Translator 的 get_cells)]
Milvus 有两套并行的缓存体系:
体系一:CachingLayer(本文重点)
- 管理 DRAM 中的数据
- 适用于需要频繁随机访问的数据(向量搜索)
- 支持驱逐到"卸载状态",数据从 DRAM 中释放
体系二:MmapChunkManager
- 通过
mmap(MAP_SHARED)将文件映射到虚拟地址空间 - 数据"存在于"磁盘,但通过内存地址访问
- OS 的缺页中断(Page Fault)机制透明地加载数据
- 适用于访问模式不规律、无法预知热点的数据
ResourceUsage 的双维度资源管理:
struct ResourceUsage {
int64_t memory_bytes; // 内存维度(DRAM)
int64_t file_bytes; // 磁盘维度(mmap文件)
};
estimated_byte_size_of_cell() 返回 {memory_bytes, file_bytes},框架同时管理两个维度的资源上限,而不仅仅是内存。BusTub 只有一个维度(帧数)。
四、设计模式详解
4.1 策略模式(Strategy Pattern)
定义:定义一系列算法或行为,将它们封装起来,并使它们可以互换,使算法的变化独立于使用算法的客户端。
BusTub 中的类比:BusTub 的 DiskManager 是"固定策略"——只能从本地文件读写,没有接口可以替换。
Milvus 中的实现:Translator<CellT> 就是策略接口:
CachingLayer 框架(Context)
│ 使用
▼
Translator<CellT>(Strategy 接口)
▲ 实现
├── ChunkTranslator(从 Parquet 加载列数据)
├── VectorIndexTranslator(从文件加载向量索引)
└── InvertedIndexTranslator(从文件加载倒排索引)
开闭原则:框架代码对"扩展"开放(随时可以添加新的 Translator),对"修改"关闭(添加新数据类型不需要改框架代码)。
实际意义:Milvus 的工程师可以在不修改缓存池框架的情况下,为新的数据格式(比如未来新的索引类型)添加缓存支持,只需实现一个新的 Translator 子类。
4.2 状态机(State Machine)
定义:用一组明确的状态和状态之间的转换规则,描述对象的生命周期,避免非法状态组合。
BusTub 中的类比:BusTub 隐式地有状态(is_dirty_、pin_count_),但没有明确的状态机,状态逻辑分散在各处。
Milvus 中的实现:CacheCell 有 4 个明确状态:
NOT_LOADED ──[首次 pin()]──▶ LOADING
│
[get_cells() 完成 mark_loaded()]
│
▼
LOADED ──[evictable=true 时 unpin()]──▶ CACHED
│
[pin_count==0]
│
NOT_LOADED ◀──[unload() 驱逐]─────────┘
每个状态的含义:
NOT_LOADED:数据不在内存,访问时触发加载LOADING:某线程正在加载,其他线程等待SharedPromise(避免重复加载)LOADED:数据在内存但不在 LRU 链表(不可驱逐的数据,如常驻索引)CACHED:数据在内存且在 LRU 链表,pin_count==0时可以被驱逐
状态机的好处:
- 防止非法转换:
LOADING状态的节点不能被驱逐(unload()只能在CACHED状态调用) - 并发安全:
LOADING状态作为"正在加载的锁",后来的 pin 请求等待而不是发起新加载 - 清晰的语义:通过状态名就能理解 Cell 当前处于什么阶段
4.3 RAII(Resource Acquisition Is Initialization)
定义:资源的获取和释放与对象的构造和析构绑定,利用 C++ 的析构函数自动调用机制保证资源被释放。
BusTub 中的应用:
PageGuard:析构时 unpinstd::lock_guard/std::unique_lock:析构时解锁
Milvus 中的扩展:
// NodePin:管理 pin_count 的 RAII 守卫
NodePin::~NodePin() {
if (node_) node_->unpin(); // 自动减少 pin_count
}
// folly::makeGuard:管理"加载中资源预约"的 RAII 守卫
auto defer_release = folly::makeGuard([this, &resource]() {
dlist_->ReleaseLoadingResource(resource); // 无论成功还是异常,都释放预约
});
// MmapChunkDescriptorPtr:shared_ptr + 自定义 Deleter
// 引用计数归零时自动调用 UnRegister,释放所有关联的 mmap block
folly::makeGuard 的威力:
// RunLoad 的简化版:
void RunLoad() {
// 第一步:预约资源(如果函数任何地方抛异常,预约也要释放)
dlist_->ReserveLoadingResource(size);
auto defer = folly::makeGuard([&]() {
dlist_->ReleaseLoadingResource(size);
});
// 第二步:实际 I/O(可能抛出异常)
auto data = translator_->get_cells(ctx, cids);
// 第三步:标记加载完成
cell->mark_loaded(data);
// defer 析构时释放"加载中"资源(切换到"已加载"计费)
// 无论第二步是否抛异常,都会执行
}
这在 BusTub 中是手动处理的,工程师容易忘记在异常路径上清理资源。
4.4 Promise-Future 演进:从同步到异步
BusTub:std::promise / std::future(一对一,同步等待)
std::promise<bool> ──set_value()──> std::future<bool> ──get()─> 阻塞等待
限制:
- 一个
promise只能对应一个future get()必须阻塞
Milvus:folly::SharedPromise / folly::SemiFuture(一对多,可组合)
folly::SharedPromise<NodePin>
├── getSemiFuture() → SemiFuture 1(线程A等待)
├── getSemiFuture() → SemiFuture 2(线程B等待)
└── getSemiFuture() → SemiFuture 3(线程C等待)
↓ 加载完成
setValue(NodePin) → 同时 fulfill 所有 SemiFuture
SemiFuture vs Future:
Future:绑定到特定的 Executor(执行器),会立即调度SemiFuture:延迟的 Future,必须显式绑定 Executor 才会执行
SemiInlineGet(future) = 将 SemiFuture 绑定到当前线程的内联执行器,等价于在当前线程同步等待——这是当前 Milvus 的过渡方案,将来全异步化后可以去掉这个调用,真正实现非阻塞 pin。
folly::collect(futures):
// 等待多个 SemiFuture 全部完成
auto all_pins = SemiInlineGet(folly::collect(std::move(futures)));
// 等价于:对每个 future 调用 get(),但 folly 的实现更高效
这让 Milvus 可以批量 pin 多个 Cell,一次等待所有加载完成,比一个个等待更高效。
4.5 双水位控制(Hysteresis Control)
这是控制论中的概念,中文叫"滞回控制"或"迟滞控制"。
问题:如果阈值只有一个值,系统会在阈值附近频繁振荡(开 → 关 → 开 → 关…)。
解决方案:设置两个阈值,触发条件和停止条件不同:
日常生活的例子:
冰箱压缩机:温度 > 8°C 时开启,温度 < 4°C 时关闭
(不是"超过 6°C 开,低于 6°C 关")
Milvus 缓存驱逐:
使用量 > high_watermark 时触发驱逐,使用量 < low_watermark 时停止驱逐
WaitingRequest 等待队列:
当资源不足时,加载请求不会立即失败,而是进入等待队列:
struct WaitingRequest {
ResourceUsage needed; // 需要多少资源
steady_clock::time_point deadline; // 超时时间
folly::Promise<void> promise; // 资源就绪时 fulfill
};
// 优先级规则:
// 1. deadline 越早 → 优先级越高(快超时的先处理)
// 2. needed 越小 → 优先级越高(小请求更容易被满足)
当驱逐释放了资源,handleWaitingRequests() 被调用,按优先级唤醒等待的请求。
4.6 Arena 分配器与对象池
背景:new/delete 每次都要向操作系统申请/释放内存,涉及系统调用和内存碎片整理,开销不小。
MmapBlock 的 Bump Allocator(线性分配器):
void* MmapBlock::Get(const uint64_t size) {
if (file_size_ - offset_.load() < size) return nullptr;
return (void*)(addr_ + offset_.fetch_add(size)); // 原子加法,O(1) 分配
}
这是最简单的 Arena 分配器:
- 从一大块预分配的内存中线性分配,
offset_单调递增 - 分配 O(1),但不支持单独释放单个对象
- 整个 Arena(MmapBlock)在 Descriptor 生命周期结束时一次性释放
适用场景:同一个 Segment 的数据生命周期一致(Segment 加载时分配,Segment 卸载时一起释放),非常适合 Arena 分配。
MmapBlock 对象池:
固定大小的 MmapBlock(小于 fix_file_size 的数据)用完后不销毁,而是重置后放回池子:
void MmapBlocksHandler::returnBlock(MmapBlockPtr block) {
block->Reset(); // 重置 offset_=0,清空数据
if (fix_size_blocks_cache_.size() < pool_capacity) {
fix_size_blocks_cache_.push(std::move(block)); // 放回池子
}
// 否则超出池子容量,直接销毁(munmap)
}
避免的开销:mmap 和 munmap 是系统调用,延迟在微秒级别。对象池通过复用已有的内存映射,避免了反复的系统调用。
五、Milvus CachingLayer 逐组件讲解
现在用 BusTub 的视角来解读 Milvus 的每个组件:
5.1 Manager(对应 BusTub 的 BufferPoolManager 的"控制中心")
class Manager {
std::shared_ptr<internal::DList> dlist_; // 全局 LRU 链表(所有 CacheSlot 共享)
shared_ptr<CPUThreadPoolExecutor> prefetch_pool_; // 预取线程池
bool eviction_enabled_; // 是否启用驱逐
chrono::milliseconds loading_timeout_; // 加载超时
};
类比:
- BusTub 的
BufferPoolManager管理所有帧,是单一的中心 - Milvus 的
Manager是单例,管理全局的驱逐策略,但具体的数据管理分散到各个CacheSlot
std::call_once 单例初始化:
static void Manager::ConfigureTieredStorage(...) {
static std::once_flag init_flag;
std::call_once(init_flag, [&]() {
// 全局只初始化一次,即使多线程同时调用
instance_.dlist_ = std::make_shared<DList>(...);
});
}
std::call_once 保证在多线程环境下,初始化代码只执行一次。比 if (!initialized) { mutex.lock(); if (!initialized) { init(); initialized = true; } mutex.unlock(); } 的双重检查锁(DCLP)更简洁安全。
5.2 CacheSlot(对应 BusTub 的 BufferPoolManager 的"每列数据管理单元")
BusTub:一个 BufferPoolManager 管理所有页。
Milvus:每个列(Column)有自己的 CacheSlot,管理该列所有 Cell:
Segment(分片)
├── Column "id" → CacheSlot<Chunk>(管理 id 列的所有 RowGroup)
├── Column "vector" → CacheSlot<VectorIndex>(管理向量索引分片)
└── Column "tag" → CacheSlot<Chunk>(管理 tag 列的所有 RowGroup)
好处:不同列可以有不同的预热策略、不同的驱逐优先级,而不是所有数据共用一套策略。
CacheSlot 的关键状态变量:
template <typename CellT>
class CacheSlot {
std::unique_ptr<Translator<CellT>> translator_; // 知道如何加载
std::vector<CacheCell> cells_; // 所有 Cell
std::atomic<bool> skip_pin_{false}; // 快速路径开关
bool evictable_; // 是否允许驱逐
};
5.3 CacheCell(对应 BusTub 的 FrameHeader)
BusTub 的 FrameHeader:
class FrameHeader {
page_id_t page_id_; // 存放的页 ID
std::atomic<size_t> pin_count_;
bool is_dirty_;
std::vector<char> data_; // 4KB 数据
};
Milvus 的 CacheCell(ListNode 的子类):
class CacheCell : public ListNode {
std::unique_ptr<CellT> cell_; // 实际数据(任意类型,不是固定4KB)
ResourceUsage loaded_size_; // 实际占用资源(内存+磁盘双维度)
State state_; // 状态机:NOT_LOADED/LOADING/LOADED/CACHED
std::atomic<int> pin_count_{0}; // 引用计数(类似 FrameHeader 的 pin_count_)
folly::SharedPromise<NodePin> loading_promise_; // 加载中等待用
};
关键区别:
- BusTub 的
FrameHeader总是有数据(data_),Milvus 的CacheCell可能没数据(NOT_LOADED) - BusTub 的
pin_count_是个数字,Milvus 额外维护了state_状态机区分"已加载未在LRU"和"已加载在LRU" - BusTub 没有
loading_promise_,因为不需要处理多线程等待同一个数据加载
5.4 DList(对应 BusTub 的 LRUKReplacer)
BusTub 的 LRUKReplacer:
class LRUKReplacer {
std::list<frame_id_t> history_list_; // 访问不足k次
std::list<frame_id_t> cache_list_; // 访问满k次
std::mutex latch_; // 一把锁保护所有
};
Milvus 的 DList:
class DList {
std::list<ListNode*> lru_list_; // 单一 LRU 链表
std::mutex list_mtx_; // 链表操作的锁
std::atomic<ResourceUsage> total_loaded_size_; // 已加载资源
std::atomic<ResourceUsage> total_loading_size_; // 加载中预约资源
std::atomic<ResourceUsage> evictable_size_; // 可驱逐资源
ResourceUsage low_watermark_;
ResourceUsage high_watermark_;
ResourceUsage max_resource_limit_;
std::priority_queue<WaitingRequest> waiting_requests_; // 等待队列
};
两者对比:
| 功能 | BusTub LRUKReplacer | Milvus DList |
|---|---|---|
| 驱逐算法 | LRU-K 双队列 | LRU 单队列 + Touch Window |
| 资源计量 | 帧数(隐式) | 字节数(显式,双维度) |
| 等待机制 | 无(驱逐失败返回 nullopt) | 有(WaitingRequest 队列) |
| 水位控制 | 无(超帧数就失败) | 双水位(低/高水位) |
| 锁策略 | 单锁保护所有 | 链表锁 + 节点读写锁分层 |
| 驱逐并发性 | 阻塞式 | try_lock 非阻塞 |
5.5 NodePin + PinWrapper(对应 BusTub 的 PageGuard)
BusTub 的 ReadPageGuard:
class ReadPageGuard {
page_id_t page_id_;
std::shared_ptr<FrameHeader> frame_;
// 析构时 unpin + SetEvictable(true)
};
Milvus 的双层封装:
// 底层:NodePin 管理单个 Cell 的 pin(不可复制,只能移动)
NodePin pin = cell->acquire_pin(); // pin_count++
// NodePin 析构 → pin_count-- → 可能插回 LRU
// 中层:CellAccessor 管理一批 Cell 的 NodePin 集合
class CellAccessor {
std::vector<NodePin> pins_; // 对应一次 PinCells 请求中所有 Cell 的 pin
CellT* get_cell_of(cid_t cid);
};
// 上层:PinWrapper<T> 对用户暴露业务数据指针
PinWrapper<const char*> pw = slot->PinCells(op_ctx, {cid});
const char* data = *pw; // 直接访问数据,不感知缓存
层次设计的目的:
NodePin:最细粒度,确保 pin 计数安全CellAccessor:批量管理多个 Cell 的 pin(一次查询可能跨多个 Cell)PinWrapper<T>:对业务代码隐藏缓存概念,像普通指针一样使用
六、总结:工业缓存池的设计哲学
6.1 演变脉络回顾
BusTub(教学) Milvus(工业)
─────────────────────────────────────────────────────────
固定4KB页 → 可变粒度Cell,由业务决定大小
LRU-K 双队列 → LRU + Touch Window,减少锁竞争
同步阻塞 std::future → 异步 folly::SemiFuture + SharedPromise
隐式帧数限制 → 显式资源预约 + 双水位驱逐
全局大锁 bpm_latch_ → 分层细粒度锁 + try_lock 无阻塞驱逐
硬编码 DiskManager → 策略模式 Translator,可插拔加载逻辑
手动 pin/unpin → 双层 RAII(NodePin + PinWrapper)
单维度 DRAM → 内存 + mmap 双轨,双维度资源计量
无物理内存感知 → 周期检测物理内存压力
6.2 核心设计原则
原则一:框架控制调度,业务实现加载
BusTub 把"何时读磁盘"和"读什么"混在一起。Milvus 把"何时加载、何时驱逐、资源如何分配"全部放在框架,把"数据在哪里、如何解析"交给业务的 Translator。这是关注点分离(Separation of Concerns)的体现。
原则二:保守优先于激进
“先预约,再加载"比"先加载,再检查"安全得多。宁愿有时候预约了但没用到(浪费一点预约空间),也不能超出内存限制导致 OOM。生产系统要优先保证稳定性。
原则三:热路径上的每一行代码都值得优化
- Touch Window:热点 Cell 每次 unpin 都要更新 LRU,用时间窗口减少锁竞争
- skip_pin_:常驻内存的数据完全绕过 pin/unpin 路径
- try_lock:驱逐绝不阻塞查询
在数据库系统中,“热路径”(一个查询中被调用最频繁的路径)的延迟直接影响 P99 响应时间。
原则四:并发安全是最高优先级
BusTub 用全局锁保证安全,简单但性能差。Milvus 使用:
- 细粒度锁(每个 Cell 一把锁)
- 读写锁(读多写少的状态查询)
- 原子操作(
ResourceUsage的 CAS 更新) - 无锁数据结构(
skip_pin_的std::atomic<bool>) - 锁序约定(避免死锁)
6.3 CachingLayer 的本质
CachingLayer 本质上是对操作系统 Page Cache 的用户态模拟与增强。
操作系统的 Page Cache 很好,但它:
- 不区分向量索引和普通数据的重要性
- 不知道哪些数据属于同一个查询(无法按查询粒度管理生命周期)
- 不能感知应用层的工作负载模式(全量预热 vs 按需加载)
Milvus 的 CachingLayer 在用户态精确复现了 OS Page Cache 的功能,并在此基础上增加了:
- 按查询语义的 pin/unpin(而不是按内存页的引用计数)
- 业务感知的驱逐策略(向量场景 vs 标量场景不同预热)
- 可配置的资源限制(内存限制 + 磁盘限制双维度)
代价是增加了实现复杂度(约数千行代码 vs 几百行的 BusTub),换来了对向量数据库工作负载的精准适配。