前言
断断续续写了好几周,终于是把 B+树部分写完了,没想到最耽误时间的还是 p1 部分,p1 部分遗留的错误导致我在写 p2 时 Contention 测试一直出问题,我还以为是 p2 哪里写错了,检查了很久,最终还是排查到 p1 了。这个故事告诉我们,不要过早优化,当然,我这也是因为原本 23fall 的代码在 24fall 有问题才想起来去修改的,情有可原(嘿嘿)。
相比于可扩展哈希,B+树层数更多,并且支持顺序读操作,相对来说效率和功能性更强,怪不得没见过用可扩展哈希的数据库。在实现上,相比于可扩展哈希,B+树的实现也不算复杂,甚至感觉更简单,也可能是写的多了。具体实现主要是增、删、查这三个操作,又以删最为复杂。24fall 有意思的一点是有 Contention 测试检查是否对 B+树的并发做了优化,即通过加大锁检查乐观锁有没有实现。
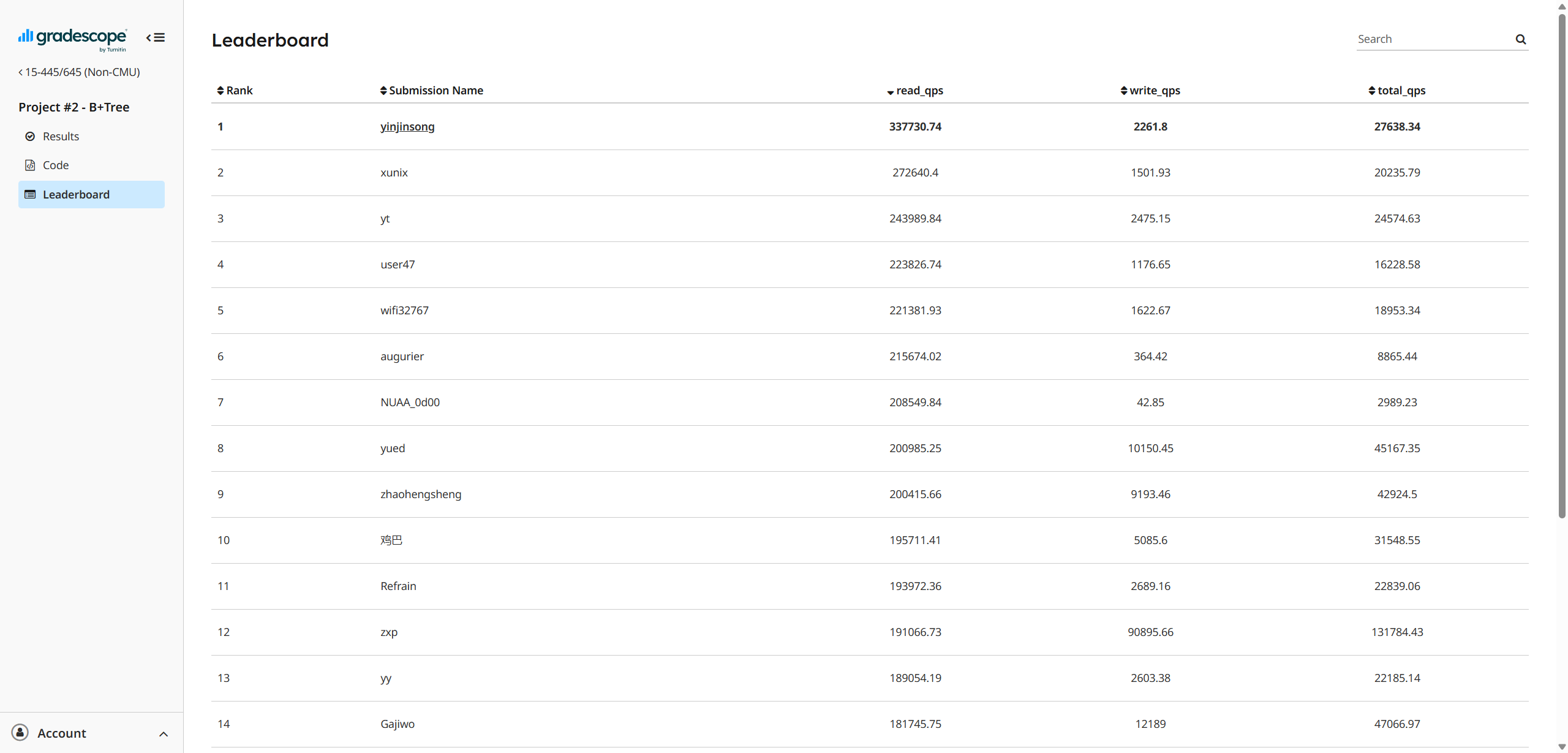
下面是最终结果,挑了个有意思的。
1. 整体架构概览
1.1 层次结构
BufferPoolManager(磁盘 <-> 内存页缓冲)
│
▼
BPlusTreeHeaderPage(固定根页ID,防止根页并发竞争)
│
▼ root_page_id_
BPlusTreeInternalPage(内部节点:m 个 key + m+1 个 child page_id)
│
▼ child page_id
BPlusTreeLeafPage(叶子节点:m 个 key + m 个 RID,单向链表)
1.2 核心类关系
| 类 | 文件 | 职责 |
|---|---|---|
BPlusTree<K,V,Cmp> | b_plus_tree.h/.cpp | 对外 API:Insert/Remove/GetValue/Begin/End |
BPlusTreePage | b_plus_tree_page.h/.cpp | 公共 Header(page_type / size / max_size) |
BPlusTreeInternalPage | b_plus_tree_internal_page.h/.cpp | 内部节点,存储路由键和子页 ID |
BPlusTreeLeafPage | b_plus_tree_leaf_page.h/.cpp | 叶子节点,存储实际 key→RID 映射 |
BPlusTreeHeaderPage | b_plus_tree_header_page.h | 仅存 root_page_id_ |
IndexIterator | index_iterator.h/.cpp | 叶子链表顺序扫描迭代器 |
Context | b_plus_tree.h | Insert/Remove 时跟踪访问路径上的页面写锁 |
1.3 模板参数
整个 B+树系统通过以下宏实现模板化:
#define INDEX_TEMPLATE_ARGUMENTS template <typename KeyType, typename ValueType, typename KeyComparator>
实例化时使用 GenericKey<N>(N=4/8/16/32/64 字节)+ RID + GenericComparator<N>,在编译期固化键长度,避免运行时动态内存分配。
2. Task 1:B+树页面层设计
2.1 内存布局思想:In-Place Reinterpret Cast
B+树的页面直接复用 BufferPool 返回的 4KB 物理页(Page 对象),通过 reinterpret_cast 将页面数据解释为各种 B+树页类型,因此:
- 所有构造函数/析构函数均被
= delete,防止 C++ 对象生命周期管理干扰内存布局。 - 使用
Init()方法代替构造函数显式初始化页面元数据。 - 这是一种"内存映射对象"模式(Memory-Mapped Object Pattern)。
2.2 BPlusTreePage(公共基类)
文件:src/storage/page/b_plus_tree_page.h
Header(12 字节):
┌─────────────────┬──────────────────┬──────────────────┐
│ page_type_ (4) │ size_ (4) │ max_size_ (4) │
└─────────────────┴──────────────────┴──────────────────┘
关键方法:
auto IsLeafPage() const -> bool; // page_type_ == LEAF_PAGE
auto GetSize() const -> int; // 当前存储的 kv 对数
auto GetMinSize() const -> int; // (max_size_ + 1) / 2 (向上取整)
细节:GetMinSize() 使用 (max_size_ + 1) / 2 而非 max_size_ / 2,保证奇数 max_size 下最小填充也满足 ≥⌈n/2⌉ 的 B+树性质。
2.3 BPlusTreeInternalPage(内部节点)
文件:src/include/storage/page/b_plus_tree_internal_page.h
Header(12 字节)+ 数据区:
┌────────────────────────────────────────────────────────┐
│ HEADER (12B) │
├────────────────┬───────────┬─────────────┬─────────────┤
│ KEY[0](无效) │ KEY[1] │ KEY[2] │ ... │
├────────────────┼───────────┼─────────────┼─────────────┤
│ PAGE_ID[0] │ PAGE_ID[1]│ PAGE_ID[2] │ ... │
└────────────────┴───────────┴─────────────┴─────────────┘
关键设计:KEY[0] 永远无效
内部节点存储 n 个 key 和 n+1 个子指针,但此实现将两个数组对齐为等长(都是 INTERNAL_PAGE_SLOT_CNT),通过让 KEY[0] 无效来对齐索引——PAGE_ID[i] 对应的子树满足 KEY[i] ≤ K < KEY[i+1],PAGE_ID[0] 对应最左子树(无下界)。
容量计算:
#define INTERNAL_PAGE_SLOT_CNT \
((BUSTUB_PAGE_SIZE - INTERNAL_PAGE_HEADER_SIZE) / (sizeof(KeyType) + sizeof(ValueType)))
// 实际 max_size = INTERNAL_PAGE_SLOT_CNT - 1(因 KEY[0] 无效,有效 key 数 = size - 1)
主要操作:
| 方法 | 说明 |
|---|---|
KeyAt(i) / SetKeyAt(i, key) | 读写 key_array_[i],i=0 时为无效 key |
ValueAt(i) / SetValueAt(i, v) | 读写 page_id_array_[i] |
Insert(i, key, value) | 在 index i 处插入(右移现有元素),size+1 |
Remove(i) | 删除 index i(左移后续元素),size-1 |
MoveRight(num) | 整体右移 num 位(用于 redistribution 接收) |
MoveLeft(num) | 整体左移 num 位(用于 redistribution 给出) |
2.4 BPlusTreeLeafPage(叶子节点)
文件:src/include/storage/page/b_plus_tree_leaf_page.h
Header(16 字节):额外比 BPlusTreePage 多一个 next_page_id_ (4B)
┌─────────────────┬──────────────────┬──────────────────┬──────────────────┐
│ page_type_ (4) │ size_ (4) │ max_size_ (4) │ next_page_id_(4) │
└─────────────────┴──────────────────┴──────────────────┴──────────────────┘
数据区:
┌───────────┬───────────┬─────────────┐ ┌───────────┬───────────┬─────────────┐
│ KEY[0] │ KEY[1] │ ... │ + │ RID[0] │ RID[1] │ ... │
└───────────┴───────────┴─────────────┘ └───────────┴───────────┴─────────────┘
叶子节点通过 next_page_id_ 构成单向链表,支持高效顺序扫描(迭代器依赖此结构)。与内部节点不同,叶子节点的 KEY[0] 是有效的。
2.5 BPlusTreeHeaderPage(头页)
文件:src/include/storage/page/b_plus_tree_header_page.h
class BPlusTreeHeaderPage {
public:
page_id_t root_page_id_;
};
极简设计,仅存一个 root_page_id_。
为什么需要独立的 HeaderPage?
在并发场景下,根节点会发生分裂和合并(root_page_id 会改变),如果没有一个持久的、固定的页面存储"当前根在哪里",多个线程同时读取根节点 ID 会产生竞争条件(race condition)。HeaderPage 的 page_id 在 B+树整个生命周期中固定不变,通过对其加锁来保护根 ID 的原子更新。
3. Task 2:核心操作实现
3.1 二分查找
所有查找操作强制使用二分查找,否则在 Gradescope 上会超时。
InternalBinarySearch(b_plus_tree.cpp:50):
// 找到满足 KEY[result-1] <= key < KEY[result] 的 result
// 返回值 result 作为 ValueAt(result-1) 的索引(指向正确子树)
int left = 1, right = internal_page->GetSize();
while (left < right) {
int mid = left + (right - left) / 2;
if (comparator_(key, internal_page->KeyAt(mid)) >= 0)
left = mid + 1;
else
right = mid;
}
return left; // 下取子节点:ValueAt(left - 1)
LeafBinarySearch(b_plus_tree.cpp:69):
// 找到第一个 KEY[result] >= key 的位置
int left = 0, right = leaf_page->GetSize();
while (left < right) {
int mid = left + (right - left) / 2;
if (comparator_(key, leaf_page->KeyAt(mid)) > 0)
left = mid + 1;
else
right = mid;
}
return left;
两个二分的语义不同:Internal 找"最后一个 ≤ key 的位置的下一个",Leaf 找"第一个 ≥ key 的位置"。
3.2 Search(GetValue)
1. ReadPage(header) -> 获取 root_page_id
2. 释放 header 的读锁(获取 root 的读锁前)
3. 循环:while (!IsLeafPage)
ReadPage(child) -> 释放父节点读锁(隐式:read_guard 被覆盖)
4. LeafBinarySearch 定位 key
5. 比较确认 key 相等后返回 RID
并发安全:使用 ReadPageGuard(RAII 读锁),每次 read_guard = bpm_->ReadPage(next) 时,旧 guard 析构释放锁,实现读锁的"手拉手传递"(hand-over-hand locking)。
3.3 Insert(插入)
实现思路概述
Insert 操作有多种情况,需要分别判断,整体流程如下:
- 判断有无根节点,无根节点就创建叶子节点作为根节点并插入数据然后
return,有根节点则往下继续执行。 - 向下搜索叶节点,同时保存中间的 InternalPage 和搜索路径(即 InternalPage 搜索过程中 Value 的下标 Index),将其放入
write_set_和index_set_中。 - 在叶子节点中搜索,如果已经存在,直接
return,如果不存在,则在搜索到的位置执行 Insert 操作。 - 接下来便是一波循环操作,利用
write_set_实现自下而上的反向搜索:如果 PageSize 大于 MaxSize,表示需要进行分裂操作,将 Page 进行分裂,将分裂后的两个 Page 的中间节点插入父节点;循环执行直到 PageSize ≤ MaxSize 时return,或者write_set_为空。 - 执行到这里说明
write_set_已为空,这时候就需要根节点进行分裂,并将新的root_page_id写入 HeaderPage。
乐观锁实现:在进行向下搜索时,如果当前节点 PageSize < MaxSize,表明这个 Page 不会发生分裂。在这种情况下,可以保证之后不会对它的父节点执行操作,直接清空 write_set_ 和 index_set_,同时将 ctx 中的 header_page_ 设置为空。此外,如果是插入最左边,需要更新最左边的 key,这个操作利用 InternalPage 中第一个 key,使后续插入和删除不需要对 write_set_ 之外的 InternalPage 节点进行修改。
完整流程
Insert(key, value)
│
├─ [空树] 创建叶子页 → 更新 header.root_page_id → return true
│
└─ [非空] 持有 header 写锁,向下遍历
│
├─ 下行(while !IsLeafPage):
│ ├─ 若当前内部节点 size < max_size("安全节点"):
│ │ 释放 header 写锁(ctx.header_page_ = nullopt)
│ │ 释放 write_set_ 前端(已不需要的祖先锁)
│ ├─ 维护 key[0]:若 key < internal.key[0],更新 key[0](最左路径特殊处理)
│ ├─ 将当前内部节点写锁入 write_set_,记录 child index 到 index_set_
│ └─ 移动到下一层
│
├─ 到达叶子节点:
│ ├─ LeafBinarySearch 找插入位置
│ ├─ 若 key 已存在 → return false(unique key 约束)
│ └─ 调用 leaf_page->Insert(index, key, value)
│
├─ [叶子未满] leaf.size <= max_size → return true(提前退出,自动释放锁)
│
└─ [叶子满了] 叶子分裂:
├─ NewPage() 创建 new_leaf
├─ 将后半部分([mid, size))移入 new_leaf
├─ 更新 next_page_id 链表:new_leaf.next = leaf.next; leaf.next = new_leaf
├─ 记录 right_key = new_leaf.key[0],right_page_id = new_leaf_id
└─ 向上传播(遍历 write_set_):
├─ 在父内部节点 index+1 处插入 (right_key, right_page_id)
├─ 若父节点 size <= max_size → return true
└─ 若父节点满 → 内部节点分裂(同上逻辑向上传播)
└─ [根节点满] 创建新根,设置两个子节点,更新 header.root_page_id
关键细节:最左路径 key[0] 的维护
// b_plus_tree.cpp:175
if (comparator_(key, internal_page->KeyAt(0)) < 0) {
internal_page->SetKeyAt(0, key);
++index;
} else {
index = InternalBinarySearch(internal_page, key);
}
内部节点的 KEY[0] 在标准实现中本应无效,但本实现在下行时维护 KEY[0] 为该内部节点管辖的最小 key。这是为了在合并/重新分配时能够正确更新父节点的 separator key。这一设计决策增加了路径维护的复杂性,也是 Insert 中最容易出 bug 的地方。
叶子分裂示意
分裂前(max_size=4,已插入第5个key):
leaf: [1, 3, 5, 7, 9] size=5
mid = 5/2 = 2
分裂后:
leaf: [1, 3] size=2
new_leaf: [5, 7, 9] size=3
parent 中插入 separator key=5, pointing to new_leaf
根节点分裂
当分裂从叶子一路冒泡到根节点时,write_set_ 为空,在 Insert 末尾单独处理:
// b_plus_tree.cpp:266
auto new_root_page_id = bpm_->NewPage();
auto internal_page = ...;
internal_page->Init(internal_max_size_);
internal_page->Insert(0, left_key, left_page_id); // 原根(左半)
internal_page->Insert(1, right_key, right_page_id); // 新分裂出来的(右半)
header_page->root_page_id_ = new_root_page_id; // 更新根
树高度 +1。
3.4 Remove(删除)
删除比插入复杂,需要处理 underflow(节点元素数低于 min_size)。
实现思路概述
Remove 操作和 Insert 差不多,主要区别在于 Remove 时有一个借节点的操作,整体流程如下:
- 判断有无根节点,没有根节点直接
return,有则继续执行。 - 和 Insert 中一样,向下搜索叶节点,同时保存中间的 InternalPage 和搜索路径放入
write_set_和index_set_中。 - 在叶子节点中搜索,如果不存在,直接
return,如果存在,则在搜索到的位置执行 Remove 操作。如果当前叶子是根节点,判断删除后是否为空,为空则重置header_page_中root_page_id,否则直接return。 - 之后是一波循环操作:如果 PageSize 小于 MinSize,表明不满足 B+树规则。首先向左边节点借 value,如果两个节点中 value 数量总和不大于 MaxSize,就将两个 Page 进行合并,否则执行借 value 操作;如果是第一个节点,则向右边借节点,同理判断合并还是借;如果 PageSize ≥ MinSize,直接
return。 - 执行到这里,说明删除到根节点了,如果 PageSize == 1,直接将根节点中第一个子节点替换根节点,修改 HeaderPage。
乐观锁实现:和 Insert 中基本一样,在进行向下搜索时,如果当前节点的 PageSize > MinSize,表明这个节点不会发生合并,直接清空 write_set_、index_set_,同时将 ctx 中的 header_page_ 设置为空。
其他优化:
- Search 使用二分查找
- 先执行 Insert 操作,再判断是否违反 B+树规则,将 InternalPageSize 和 LeafPageSize 上限各减一,避免出现 PageSize > MaxSize 时可能的越界
- Remove 中借操作时,提前移位留足空间,保证每个元素只执行一次移位操作
完整流程
Remove(key)
│
├─ [空树] return
│
└─ [非空] 持有 header 写锁,向下遍历
│
├─ 下行(while !IsLeafPage):
│ ├─ 若当前内部节点 size > min_size("安全节点"):
│ │ 释放 header 写锁 + write_set_ 前端的祖先锁
│ ├─ 提前预存 sibling:
│ │ 若 index > 1 → 存左兄弟 write_guard 入 write_set_
│ │ 否则若 index < size → 存右兄弟 write_guard 入 write_set_
│ ├─ 存当前节点 write_guard 入 write_set_,记录 index 到 index_set_
│ └─ 移动到子节点
│
├─ 到达叶子节点:
│ ├─ LeafBinarySearch + 确认 key 存在
│ └─ leaf_page->Remove(index)
│
├─ [叶子是根 且 变空] header.root_page_id = INVALID → return(树空)
├─ [叶子 size >= min_size] → return(无 underflow)
│
└─ [叶子 underflow] 从 write_set_ 取出父节点 + sibling:
├─ 优先处理左兄弟(index > 0):
│ ├─ 若 left.size + leaf.size > max_size → redistribute(重新分配)
│ │ mid = (left.size + leaf.size) / 2
│ │ 将 left 的后半部分移入 leaf 的前面
│ │ 更新父节点 separator key(index 位置)= leaf.key[0]
│ └─ 否则 merge:
│ 将 leaf 全部内容追加到 left
│ 更新 left.next_page_id = leaf.next_page_id
│ 删除父节点中 index 处的 key(Remove(index))
│
└─ 处理右兄弟(index == 0 且 parent.size > 1):
├─ 若 right.size + leaf.size > max_size → redistribute
│ 将 right 的前半部分移入 leaf 末尾
│ 更新父节点 separator key(index+1 位置)= right.key[0]
└─ 否则 merge:
将 right 全部内容追加到 leaf
更新 leaf.next_page_id = right.next_page_id
删除父节点中 index+1 处的 key
内部节点 underflow 向上传播
叶子层处理完毕后,若父内部节点也发生 underflow,使用 while 循环向上传播,逻辑与叶子层镜像:
// b_plus_tree.cpp:412
while (internal_page->GetSize() < internal_page->GetMinSize() && !ctx.write_set_.empty()) {
// 与叶子层相同的 redistribute / merge 逻辑,但操作的是 InternalPage
}
根节点缩减
当根节点内部节点只剩 1 个指针(size == 1)时,唯一的子节点晋升为新根,树高度 -1:
// b_plus_tree.cpp:470
if (internal_guard.GetPageId() == root_page_id && internal_page->GetSize() == 1) {
header_page->root_page_id_ = internal_page->ValueAt(0);
}
Redistribute vs Merge 决策
条件:left.size + current.size > max_size
→ Redistribute(可以平衡两节点,不需要合并)
条件:left.size + current.size <= max_size
→ Merge(两节点合并为一个仍不超限)
等价于:当两节点合并后总量 ≤ max_size 时合并,否则重新分配。
4. Task 3:索引迭代器
4.1 设计
文件:src/include/storage/index/index_iterator.h / src/storage/index/index_iterator.cpp
class IndexIterator {
page_id_t page_id_; // 当前所在叶子页 ID(INVALID_PAGE_ID 表示 End)
int index_; // 当前在页内的偏移
BufferPoolManager *bpm_;
};
4.2 关键操作
IsEnd():page_id_ == INVALID_PAGE_ID
operator++():
if (index_ + 1 < leaf_page->GetSize()) {
++index_; // 同页内移动
} else {
page_id_ = leaf_page->GetNextPageId(); // 跨页:跳到下一叶子
index_ = 0;
}
operator*():每次调用都重新 ReadPage,返回 pair<const KeyType&, const ValueType&>。
operator==():比较 page_id_ 和 index_ 两个字段。
4.3 Begin / End 实现
// Begin():找最左叶子(始终向 ValueAt(0) 走)
// Begin(key):向下找包含 key 的叶子,返回指向该 key 的迭代器
// End():返回默认构造的 IndexIterator(page_id = INVALID_PAGE_ID)
5. Task 4:并发控制(Latch Crabbing)
5.1 Latch Crabbing / Latch Coupling 算法
Latch Crabbing(也叫 Latch Coupling)是 B+树并发控制的经典方案,核心思想:
向下遍历时,先获取子节点的锁,再按条件决定是否释放父节点的锁,如同螃蟹"一松一抓"地前进。
安全节点(Safe Node)定义:
- 插入操作:节点当前
size < max_size(插入后不会分裂) - 删除操作:节点当前
size > min_size(删除后不会 underflow)
5.2 实现细节
Search(只读):
获取 header 读锁 → 读取 root_page_id
获取 root 读锁 → 释放 header 读锁
循环:获取 child 读锁 → 释放父节点读锁
到达叶子 → 搜索 → 释放叶子读锁
使用 ReadPageGuard,直接赋值 read_guard = bpm_->ReadPage(next) 会触发旧 guard 析构(自动释放读锁),干净利落。
Insert(写):
获取 header 写锁(Context.header_page_)
获取 root 写锁,入 write_set_
循环(while !IsLeafPage):
if (current.size < max_size):
释放 header 写锁(ctx.header_page_ = nullopt)
释放 write_set_ 前端的所有"安全祖先"
获取 child 写锁,入 write_set_
操作叶子
若需要分裂:write_set_ 中已有路径上的节点写锁,直接操作
自动析构时释放所有剩余写锁
Remove(写):与 Insert 类似,但安全条件为 size > min_size。额外将 sibling 的写锁也提前放入 write_set_,避免后续需要回头加锁(deadlock 风险)。
5.3 HeaderPage 的特殊处理
HeaderPage 是访问树的入口,只有在确认操作可能修改根(即没有安全节点在根路径上)时才需要持有其写锁。本实现中:
- 遇到第一个"安全"内部节点时,立即释放
header_page_写锁(ctx.header_page_ = std::nullopt) - 若整个路径都不安全(最终到达根需要分裂/合并),则写锁持续到操作结束
5.4 Context 类的设计作用
class Context {
std::optional<WritePageGuard> header_page_; // header 写锁,nullopt = 已释放
page_id_t root_page_id_; // 避免重复读 header
std::deque<WritePageGuard> write_set_; // 路径上的写锁(LIFO 访问)
std::deque<int> index_set_; // 对应每个写锁节点选择的 child index
std::deque<ReadPageGuard> read_set_; // 预留(本实现未大量使用)
};
write_set_ 和 index_set_ 构成"路径记录",使得分裂/合并时可以逆向回溯父节点进行更新,无需在节点中存储父指针(parent pointer)。
6. 设计分析
6.1 RAII + PageGuard(内存安全与锁安全)
ReadPageGuard / WritePageGuard 遵循 RAII 原则:
- 构造时:从 BPM 获取页面,加锁
- 析构时:自动解锁并 Unpin 页面
这使得代码中无需手动 Unpin 和 Unlock,消除了大量资源泄漏和死锁风险。Context 的 write_set_ 使用 deque<WritePageGuard>,在 Context 析构时所有路径锁自动释放——即使提前 return 或抛出异常也不会泄漏。
6.2 Context 类:局部状态封装
将一次 Insert/Remove 操作的"上下文状态"封装在 Context 对象中,而非使用全局变量或在 BPlusTree 类中新增成员变量。这是典型的局部状态对象模式,优点:
- 每次操作独立隔离,天然线程安全
- 操作完成后 Context 析构,所有锁和页面自动释放
- 逻辑清晰,可读性好
6.3 模板化 + 显式实例化
使用 C++ 模板支持不同键长度,并通过显式实例化(在 .cpp 末尾 template class BPlusTree<GenericKey<4>, ...>)将实例化集中在一处,加速编译。
6.4 叶子页单向链表支持范围扫描
叶子页通过 next_page_id_ 形成单向链表,使得范围扫描(Range Scan)和顺序扫描无需回到树的根部重新查找,时间复杂度为 O(k)(k 为结果数量)。这是 B+树相比 B-树的重要优势。
6.5 分离的 HeaderPage 防止根节点竞争
根节点频繁发生分裂/合并,如果直接在 BPlusTree 对象中用一个成员变量存储 root_page_id,并发访问时需要对整个 BPlusTree 加锁。引入 HeaderPage 后,可以用页面粒度的锁(而非对象锁)保护根节点 ID,粒度更细,并发度更高。
思考
到这里,CMU 15-445 的 B+Tree 部分算是告一段落了。相比于可扩展哈希,B+树的层次更多,并发场景也更复杂,但整体思路是清晰的——无论是 Latch Crabbing、RAII PageGuard,还是 Context 封装路径状态,都是值得反复回味的工程设计。写博客的过程也是对这些细节重新梳理的过程,希望这篇文章对后来做这个项目的同学有所帮助。